성공적인 항체 개발 Cell-based KD 최적화는 단순한 결합력 측정을 넘어, 실제 세포 환경(Native Target)에서의 기능성을 검증하는 과정입니다. 초기 단계에서 cell-based assay를 통해 유효 후보를 선별하고, 리드 최적화 단계에서 kon/koff kinetics를 분석함으로써 IND 제출 시 규제기관이 요구하는 재현성 있는 데이터 패키지를 확보하는 것이 이 전략의 핵심입니다.
왜 항체 개발에서 Cell-based KD 최적화가 필수적인가?
항체 신약 개발 현장에서 흔히 발생하는 문제 중 하나는 ELISA 상에서 매우 우수한 결합력(Affinity)을 보였던 물질이 실제 세포 실험이나 동물 모델에서는 효능을 발휘하지 못하는 것입니다. 이는 재조합 단백질(Recombinant protein)과 실제 세포 표면의 Native Target 구조 차이에서 기인합니다.
따라서 초기 후보물질 선별 단계부터 cell-based 시스템을 도입하여 “세포에서 작동하는 진짜 결합”을 찾는 Binding Affinity 전략이 필요합니다. 이는 개발 후반부의 리스크를 줄이고 IND(임상시험계획승인) 제출 데이터의 신뢰도를 높이는 유일한 길입니다.
단계별 항체 개발 Cell-based KD 최적화 로드맵
1. Hit/스캔 단계: Native Epitope 필터링
고정화된 항원 대신 세포 표면에 발현된 타겟을 직접 타격하는 클론을 선별합니다. 예를 들어, 1,000개의 클론 중 ELISA 양성은 200개일 수 있으나, 실제 cell-based binding을 통과하는 클론은 50개 미만으로 줄어들 수 있습니다. 이 필터링이 초기 개발 성공률을 결정합니다.
2. Lead 선정 단계: Kinetics의 정밀 분석
단순히 KD 값만 보는 것이 아니라, 결합 속도(kon)와 해리 속도(koff)를 분리해서 봐야 합니다. Zhang et al. (2022)에 따르면, 임상적으로 유의미한 효능을 위해서는 적절한 Residence time(1/koff) 확보가 필수적입니다.
| 분류 | Soluble Antigen (ELISA/SPR) | Cell-based Assay |
|---|---|---|
| 타겟 구조 | 정제된 단백질 (변성 위험 있음) | Native 상태 (막 관통 구조 유지) |
| 결합 특성 | Intrinsic Affinity 위주 | Avidity 및 클러스터링 반영 |
| 실무적 가치 | 대량 스크리닝 용이 | 실제 효능(Potency) 예측 가능 |
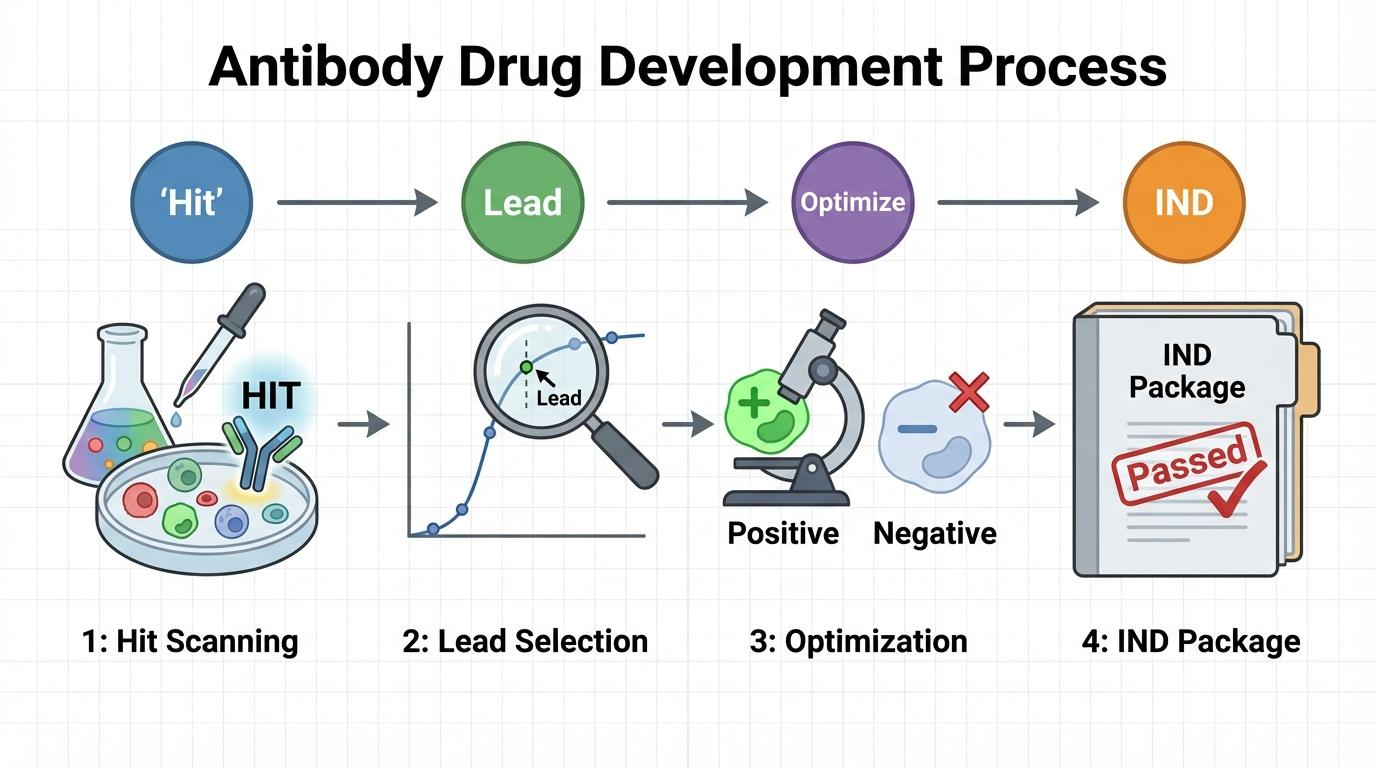
[그림 1] 항체 개발 단계별 Cell-based 최적화 프로세스 인포그래픽
IND 제출용 데이터 구성 가이드
규제기관(FDA/MFDS)은 단순히 “KD가 10-10 M이다”라는 결과보다, 그 값을 도출하기 위한 **실험의 적절성**을 더 중요하게 봅니다. 신약 후보물질 KD 데이터를 패키징할 때는 다음 요소를 포함해야 합니다.
- Antigen Positive/Negative Cell Pair: 타겟에 대한 특이성(Specificity) 입증 데이터.
- Saturation Curve & Fitting Model: 사용된 비선형 회귀 모델(Non-linear regression)의 신뢰도(R2) 제시.
- Assay Validation: Inter-assay/Intra-assay 정밀도(Precision) 및 재현성 데이터.
- Functional Correlation: 결합력(KD)과 실제 기능 저해(IC50) 간의 상관관계 설명.
핵심 용어 정리 (Glossary)
- 1. Cell-based KD
- 인공적인 환경이 아닌, 실제 살아있는 세포 표면에서 항체와 수용체가 평형 상태에 도달했을 때의 해리 상수입니다.
- 2. Native Epitope
- 단백질이 세포막에 삽입되어 자연적인 3차원 구조를 유지하고 있을 때 형성되는 항원 결정기입니다.
- 3. Internalization
- 항체가 세포 표면 타겟에 결합한 후 세포 내부로 이끌려 들어가는 현상으로, 항체-약물 접합체(ADC) 개발의 핵심 지표입니다.
자주 묻는 질문 (FAQ)
Q1: ELISA 결과와 cell-based KD 값이 크게 다를 때는 어떻게 해석해야 하나요?
A: 주로 타겟 단백질의 구조적 차이나 세포 표면의 타겟 밀도(Density) 때문입니다. IND 관점에서는 세포 기반 데이터를 우선하되, 왜 차이가 발생하는지(예: Avidity 효과 등)를 설명하는 데이터를 보강하는 것이 좋습니다.
Q2: IND 단계에서 가장 빈번하게 발생하는 ‘Clinical Hold’ 사유는 무엇인가요?
A: 충분한 CMC 데이터 부족 외에도, Potency Assay의 밸리데이션 결여가 큰 비중을 차지합니다. Binding 데이터가 실제 기전(MOA)을 충분히 대변한다는 것을 입증해야 합니다.
본 포스팅은 항체 신약 개발 현장의 최신 트렌드를 반영하고 있으며, 상표권 및 인용된 연구 데이터의 저작권은 각 소유자에게 있습니다. 구체적인 실험 프로토콜은 연구 타겟에 따라 조정이 필요할 수 있습니다.
문의 QR 코드 (메시지 연결)
