
[핵심 요약] ELISA Binding Affinity KD 값이란 무엇인가?
Binding Affinity(결합 친화도)를 나타내는 KD 값은 리셉터의 50%를 점유하기 위해 필요한 리간드의 농도를 의미하며, KD 값이 낮을수록 결합 강도가 높음을 뜻합니다. 본 포스트에서는 ELISA Saturation Binding Assay 데이터를 활용하여 원사이트 바인딩 모델(One-site binding model) 수식에 대입하고, 데이터 피팅을 통해 정확한 KD 값을 도출하는 실무 프로세스를 상세히 설명합니다.
오늘도 실험실에서 밤을 지새우는 바이오 전공 대학원생이라면 한 번쯤 이런 고민에 빠져보셨을 겁니다. “데이터는 나왔는데, 이 흡광도(OD) 값을 어떻게 신뢰할 수 있는 KD 값으로 변환해야 하지?” 항체 치료제의 효능을 입증하는 가장 기초적이면서도 중요한 지표가 바로 ELISA Binding Affinity입니다. 단순히 그래프를 그리는 것을 넘어, 데이터의 물리화학적 의미를 파악하고 정확한 피팅(Fitting)을 수행하는 법을 공유합니다.
1. 성공의 열쇠, Binding Affinity KD 값의 핵심 의미
KD(Dissociation Equilibrium Constant, 해리평형상수)는 분자 간 상호작용 연구에서 결합력을 정량화하는 가장 표준적인 파라미터입니다. Jarmoskaite et al. (2020)에 따르면, KD 값은 표적 단백질의 총 결합 부위 중 정확히 50%가 리간드와 결합했을 때의 리간드 농도를 말합니다.
- 낮은 KD 값: 매우 낮은 농도에서도 타겟과 강하게 결합함을 의미 (고친화도)
- 높은 KD 값: 결합이 쉽게 해리되며 높은 리간드 농도가 필요함을 의미 (저친화도)
예를 들어, 항체 A의 KD 값이 1 nM이고 항체 B가 10 nM이라면, 항체 A가 10배 더 강력한 결합력을 가졌다고 해석할 수 있습니다.
💡 연구 현장 Pro-tip: 초기 스크리닝 전략
예측되는 KD 값의 0.1배에서 100배 사이의 리간드 농도 범위를 설정하세요. 농도 범위가 넓고 촘촘할수록 비선형 회귀 분석의 R-squared(결정계수) 값이 높아져 데이터의 신뢰도가 상승합니다.
2. ELISA Saturation Binding Assay 실험 공정
결합 친화도를 측정하기 위해 가장 널리 사용되는 방법은 Saturation Binding Assay입니다. 리간드 농도를 높여가며 리셉터가 포화(Saturation)되는 지점을 찾는 것이 핵심입니다.
| 단계 | 주요 활동 | 핵심 체크포인트 |
|---|---|---|
| 1. Screening | 최적 리셉터 코팅 농도 결정 | Signal-to-Noise 비율 확보 |
| 2. Coating/Blocking | Antigen 또는 Receptor 고정 | 비특이적 결합 방지 |
| 3. Ligand Incubation | 순차 희석(Serial Dilution) 적용 | 충분한 평형 시간(Equilibrium) 보장 |
| 4. Detection | 2차 항체 및 기질(TMB 등) 반응 | 발색 반응의 선형 구간 측정 |
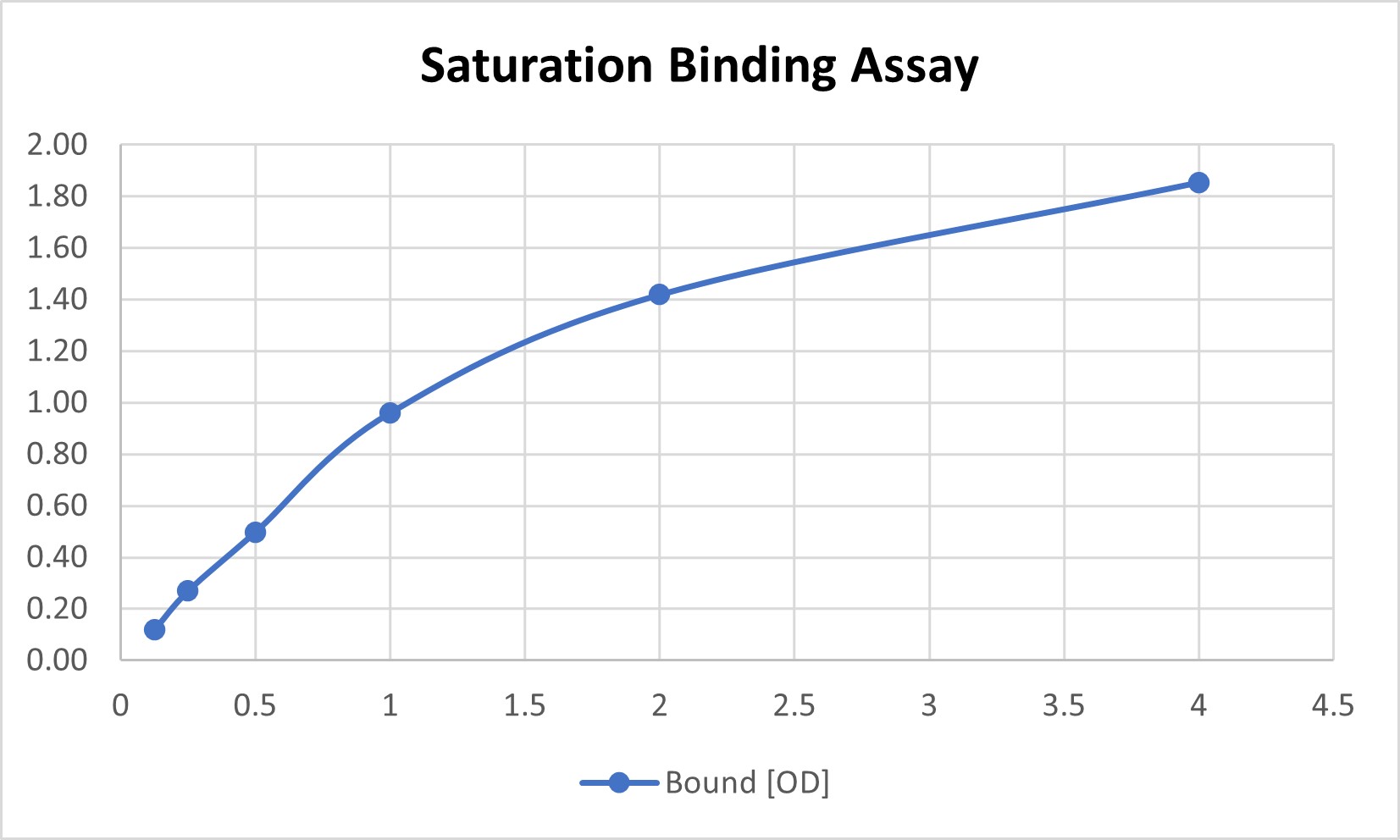
3. One-site Binding Model을 이용한 KD 값 도출
수집된 OD 데이터는 One-site binding model이라는 비선형 회귀 모델을 통해 분석됩니다. 이 모델은 리간드가 수용체의 단일 부위에 1:1로 결합한다고 가정합니다.
Y = ( Bmax * [L] ) / ( KD + [L] )
- • Y: 측정된 결합값 (Bound Signal, OD)
- • Bmax: 리간드가 결합할 수 있는 최대 흡광도값
- • [L]: 투입된 리간드 농도 (Ligand Concentration)
- • KD: 평형해리상수 (Dissociation Constant)
4. 실전 데이터 분석 예시
다음은 실제 연구소에서 얻은 결합 실험 데이터의 예시입니다. 이를 엑셀이나 GraphPad Prism에 입력하여 KD 값 피팅을 진행합니다.
| Ligand [nM] | Bound [OD] |
|---|---|
| 0.125 | 0.12 |
| 0.25 | 0.27 |
| 0.5 | 0.50 |
| 1.0 | 0.96 |
| 2.0 | 1.42 |
| 4.0 | 1.85 |
상기 데이터를 수식에 대입하여 Bmax와 KD 값을 최적화하는 과정을 거치면, 아래와 같은 피팅 곡선을 얻을 수 있습니다. 그래프의 기울기가 꺾이며 평행해지는 구간(Plateau)이 명확해야 KD 값의 신뢰도가 보장됩니다.
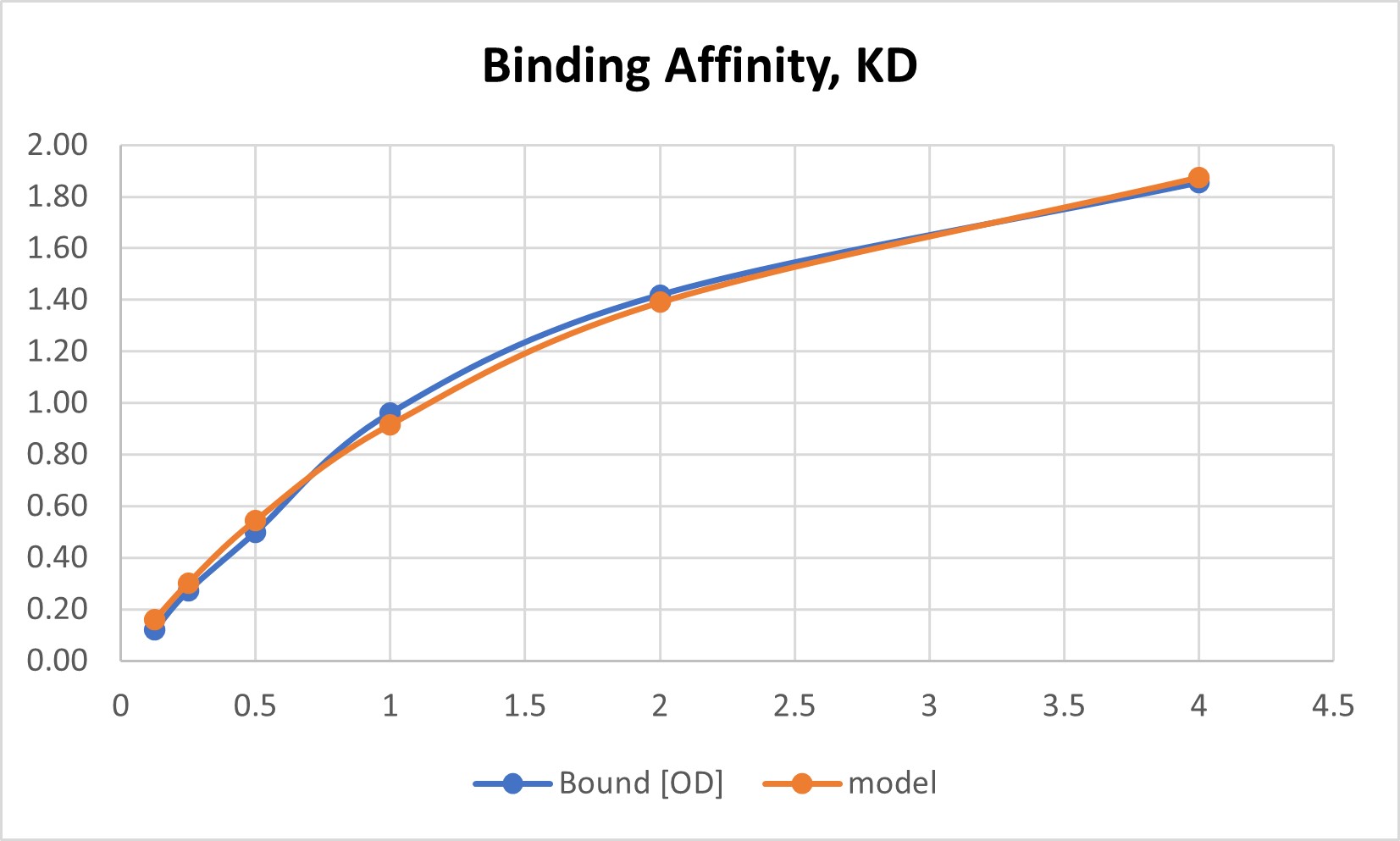
5. 자주 묻는 질문 (FAQ)
Q1. KD와 Ka의 차이는 무엇인가요?
KD는 해리상수로 값이 작을수록 결합이 강함을 의미하고, KA(Association constant)는 결합상수로 값이 클수록 결합이 강함을 의미합니다. 즉, KD = 1 / KA 의 역수 관계입니다.
Q2. 포화 상태가 나타나지 않으면 어떻게 하나요?
리간드 농도를 더 높여서 실험하거나, 비특이적 결합(Non-specific binding)을 의심해 봐야 합니다. 모델 피팅 시 Bmax를 고정하지 말고 소프트웨어가 찾도록 설정하세요.
더 전문적인 KD 값 분석 서비스나 커스텀 실험 설계가 필요하신가요?
실시간 실험 상담 및 문의하기참고문헌
- Jarmoskaite, I., AlSadhan, I., Vaidyanathan, P. P., & Herschlag, D. (2020). How to measure and evaluate binding affinities. eLife, 9, e57264.
- Eble, J. A. (2018). Titration ELISA as a Method to Determine the Dissociation Constant of Receptor Ligand Interaction. Journal of Visualized Experiments, (132), e57334.
- YClueBio. (2023). Ligand binding affinity package. Retrieved from https://ycluebio.com/ligand-binding-affinity-package/
