핵심 인사이트 (Key Insight)
SPR 분석 데이터 품질은 단순한 수치 이상의 의미를 가집니다. Chi2, SE, U-value와 같은 지표는 시각적으로 완벽해 보이는 커브 뒤에 숨겨진 비특이적 결합이나 질량 이동 제한(MTL)과 같은 실험적 결함을 정량적으로 드러내어 분석의 신뢰성을 보장합니다.
인사이트 키워드: SPR 분석 데이터 품질, SPR kinetics 신뢰성, Biacore 결과 해석, Chi2 해석 기준
왜 SPR 분석 데이터 품질 지표 점검이 필수인가요?
SPR 분석 데이터 품질을 평가할 때 가장 흔히 범하는 실수는 단순히 커브가 매끄럽게 그려졌는지(Good looking curve)만을 확인하는 것입니다. 하지만 시각적인 판단은 주관적일 뿐만 아니라, 통계적으로 유의미하지 않은 데이터를 양산할 위험이 큽니다.
시각적 커브 판단의 한계와 잔차(Residuals)의 비밀은 무엇인가요?
센서그램 커브가 모델 피팅 라인과 잘 겹쳐 보여도 잔차(Residuals)가 랜덤하지 않고 S자형 등의 체계적인 패턴을 보인다면, 이는 모델링 자체가 잘못되었거나 질량 이동 제한(Mass Transport Limitation)이 발생했음을 강력하게 시사합니다. 이러한 결함은 Chi2 수치와 잔차 패턴 분석을 통해서만 객관적으로 확인될 수 있습니다.
파라미터(ka, kd) 값만으로는 판단할 수 없는 통계적 정밀도의 정체는?
추정된 ka(결합상수)와 kd(해리상수) 값이 예상 범위 내에 있더라도, T-value가 10 미만이거나 표준오차(SE)가 과도하게 크다면 그 결과는 신뢰할 수 없습니다. 이는 농도 설계가 잘못되었거나 실험 노이즈가 데이터의 진정한 신호를 압도하고 있다는 신호입니다.
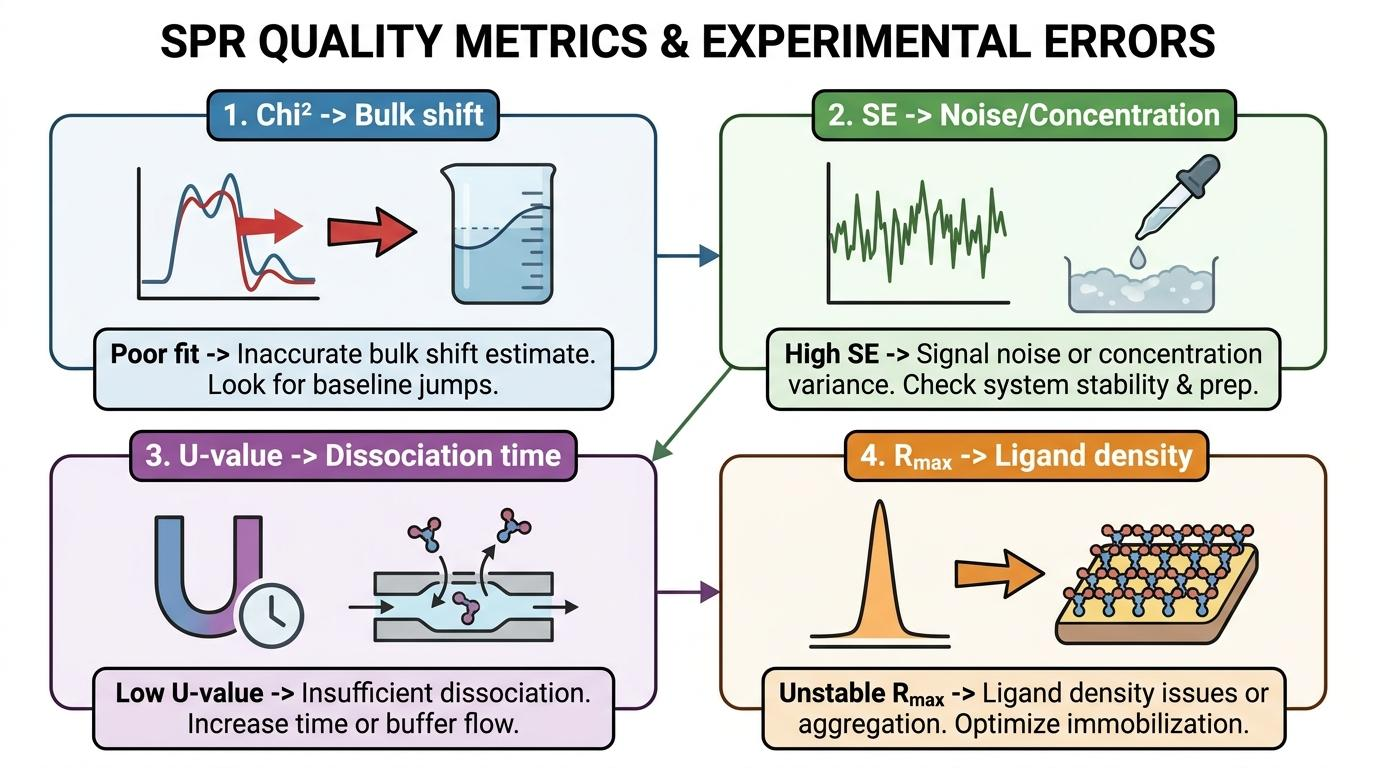
[그림 1] SPR 분석 데이터 품질 평가 4대 핵심 지표
SPR 신뢰도를 결정하는 4대 핵심 품질 지표는 무엇인가요?
데이터의 품질을 객관적으로 증명하기 위해서는 다음 4가지 핵심 지표를 반드시 확인해야 합니다.
Chi2 – 모델 적합도의 정량적 기준은 어떻게 되나요?
Chi2는 관측값과 모델 피팅값 사이의 오차 제곱합을 나타냅니다. 일반적으로 Rmax의 5~10% 이내(최적 기준 2% 미만)를 유지해야 하며, 이 수치가 높을수록 Baseline drift나 모델 불일치가 발생했음을 의미합니다.
SE, T-value 및 U-value – 파라미터의 독립성과 정밀도는 왜 중요한가요?
- SE (Standard Error): ka, kd의 오차를 측정하며 10% 미만을 권장합니다.
- T-value: 파라미터 값/SE 수치로, 10 이상이어야 통계적으로 유의미합니다.
- U-value: ka와 kd 사이의 상관성을 평가합니다. 15~25를 초과하면 두 파라미터가 서로 얽혀 있어 유일한 해(Unique solution)를 찾지 못했음을 뜻합니다.
Pro-tip: 실무자를 위한 U-value 개선 팁
U-value가 너무 높게 나온다면 해리(Dissociation) 시간을 더 길게 설정해 보세요. 충분한 해리 데이터가 확보되지 않으면 ka와 kd를 독립적으로 계산하기 어려워져 수치가 상승하게 됩니다.
지표별 파라미터 문제 매핑 및 원인 진단 방법은?
특정 지표의 이상은 실험의 특정 단계에서 발생한 오류를 반영합니다.
| 지표 | 임계치 | 의심되는 주요 문제 |
|---|---|---|
| Chi2 | Rmax의 < 5% | Bulk shift, 모델 불일치, MTL |
| SE (Standard Error) | < 10% | 농도 설계 실패, 데이터 노이즈 과다 |
| U-value | < 15 | 해리/포화 데이터 부족, 상관성 높음 |
| Rmax 변동 | < 10% | 표면 재생 실패, Ligand 비활성화 |
고품질 SPR 데이터 확보를 위한 실전 향상 전략은?
센서칩 최적화와 표면 재생(Regeneration) 프로토콜을 어떻게 개선하나요?
적절한 재생 공정은 잔류 단백질을 완벽히 제거하여 Rmax의 재현성을 95% 이상으로 높여줍니다. 이는 비특이적 신호를 최소화하여 결과적으로 Chi2 값을 2~3% 포인트 하락시키는 효과를 가져옵니다.
농도 반복 실험 및 전문 장비(Biacore T200) 활용의 이점은 무엇인가요?
5~7개의 농도 시리즈를 반복 실험하고 TraceDrawer와 같은 전문 소프트웨어의 Global fitting을 적용하면 SE를 10% 미만으로 정밀하게 제어할 수 있습니다. 특히 Biacore T200과 같은 고감도 장비를 사용하면 Baseline drift를 최소화하여 실험 시행착오를 최대 70%까지 줄일 수 있습니다.
품질 기준 준수 확인 및 문제 해결 체크리스트
실험 완료 후 데이터 리포트를 받으셨다면, 다음 기준을 하나씩 체크해 보세요.
- Chi2가 Rmax의 5% 미만인가? (그 이상일 경우 Bulk shift 보정 필요)
- U-value가 15 이하로 고유한 값을 추정하고 있는가?
- SE 수치가 ka, kd 값의 10% 이내인가?
- 반복된 실험 사이클 간 Rmax 변동이 10% 미만인가?
자주 묻는 질문 (FAQ)
Q1. Chi2 수치가 높게 나왔는데 데이터로 사용 가능한가요?
A1. Chi2가 높다는 것은 모델이 실험 데이터를 충분히 설명하지 못함을 의미합니다. 잔차 패턴을 확인하여 Bulk shift나 MTL 보정을 적용한 후에도 높다면, 모델을 변경하거나 실험을 재설계해야 합니다.
Q2. U-value가 25 이상이면 결과가 무효인가요?
A2. 무효라기보다는 ka와 kd의 독립성이 결여된 상태입니다. 즉, ka/kd의 비(KD)는 비교적 정확할 수 있으나 개별 상수는 신뢰하기 어렵습니다. 해리 구간을 늘려 재실험을 권장합니다.
Q3. Rmax 재현성이 떨어지는 이유는 무엇인가요?
A3. 주로 표면 재생(Regeneration) 단계에서 Ligand가 손상되거나 비가역적으로 변성될 때 발생합니다. 재생 시약의 농도나 반응 시간을 최적화해야 합니다.
핵심 용어 정리 (Glossary)
Mass Transport Limitation (MTL): 분석 물질이 용액에서 센서 표면으로 전달되는 속도가 결합 속도보다 느려져 실제 kinetics를 왜곡하는 현상입니다.
Bulk Shift: 샘플과 러닝 버퍼 간의 굴절률 차이로 인해 발생하는 신호 점프 현상입니다.
Global Fitting: 여러 농도의 데이터를 하나의 모델에 동시에 피팅하여 ka, kd 값의 정확도를 높이는 방식입니다.
BiacoreTM는 Cytiva의 등록 상표이며, 본 포스팅은 정보 제공 및 기술 교육 목적으로 작성되었습니다.