AI 항체 개발 데이터의 구조와 품질은 성공적인 항체 설계 모델의 성능을 결정하는 핵심 요소입니다. 단편적인 실험 결과의 모음이 아닌, 교차 검증된 데이터 세트(Data Set)의 구축이 필수적입니다. 본 가이드에서는 SPR, FACS 등 다양한 플랫폼의 데이터를 통합하고 표준화하는 실무 전략을 제시합니다.
인사이트 키워드: AI 항체 개발 데이터, 데이터셋 구축, 결합 동력학, 품질 관리
목차
1. AI 항체 개발 데이터 구축의 중요성
기계 학습(Machine Learning) 기술이 발전함에 따라 항체 설계의 패러다임이 변화하고 있습니다. 과거에는 무작위 스크리닝에 의존했습니다. 현재는 구조 기반 모델(Structure-based model)을 통한 합리적 설계가 유망한 방식으로 자리 잡았습니다.
항체 설계의 현황과 도전 과제
항체의 상보성 결정 부위(CDR) 최적화에 인공지능을 도입하는 연구가 활발합니다. 그러나 모델을 훈련할 고품질 AI 항체 개발 데이터의 부재가 가장 큰 장애물로 지적됩니다. 신뢰할 수 있는 데이터 세트의 구축 없이는 알고리즘의 발전도 한계에 부딪힐 가능성이 제기되었습니다.
본 가이드의 목적과 활용 대상
이 글은 항체 개발 연구원, 바이오 엔지니어 및 데이터 과학자를 위해 작성되었습니다. 복잡한 이론보다는 실무에 즉시 적용 가능한 데이터 구축 전략에 집중하여 설명합니다. 실험 데이터의 정제부터 AI 모델 학습을 위한 최적화 방법론까지 상세히 다룹니다.
2. 데이터 수집 전략: 내부와 공개 데이터의 균형
강력한 예측 모델을 구축하려면 양적 팽창과 질적 통제가 동시에 이루어져야 합니다. 이를 위해 내부 실험 데이터와 외부 공개 데이터베이스를 조화롭게 활용하는 전략이 필요합니다.
내부 실험 데이터의 가치와 한계
내부 데이터는 엄격히 통제된 조건에서 생성되므로 높은 신뢰도를 보장합니다. 또한 기업의 독점적인 자산으로서 가치를 지닙니다. 하지만 대규모 생성을 위한 비용 부담이 크고, 단기간에 스케일(Scale)을 확장하기 어렵습니다. 따라서 주로 모델의 미세 조정(Fine-tuning)과 교차 검증용으로 활용하는 것이 권장됩니다.
공개 데이터베이스(Database)의 포괄적 활용
초기 모델의 사전 학습(Pre-training)을 위해서는 거대한 공개 데이터가 필수적입니다. SAbDab은 항체-단백질 복합체 구조를 제공합니다. OAS(Observed Antibody Space)는 차세대 염기서열 분석(NGS) 기반의 거대한 면역 레퍼토리를 포함합니다. 이러한 데이터는 모델의 벤치마킹 지표로도 활용됩니다.
대량 분석(High-throughput assay) 파이프라인
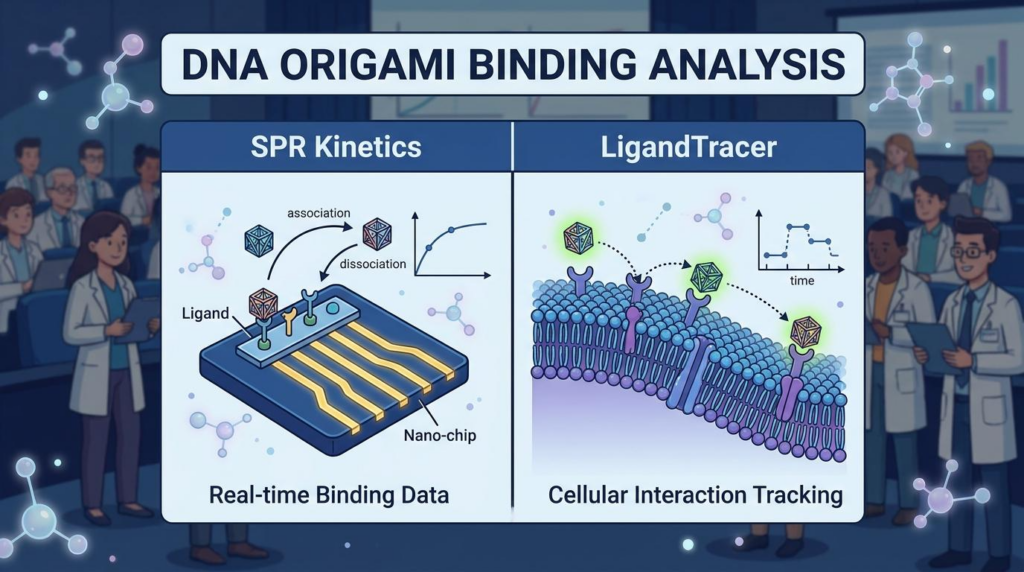
효율적인 데이터 확보를 위해 3단계 파이프라인을 구축합니다. 1차로 ELISA를 통해 수만 개의 클론을 대량 스크리닝합니다. 2차는 SPR 장비를 사용하여 결합 동력학(Binding Kinetics)을 정밀 분석합니다. 마지막으로 FACS를 통해 세포 표면 환경에서의 실제 효능을 검증합니다.
[추천 자료] 환경에 따라 항체의 결합력은 다르게 측정될 수 있습니다. 정밀한 데이터를 구축하려면 세포막 수용체와 재조합 단백질의 Binding Kinetics 차이 분석 원리를 이해하는 것이 중요합니다. 다음 링크에서 상세한 분석 기법을 확인해 보십시오.
상세 자료 확인하기3. 데이터 통합: SPR, FACS, ELISA 간 이질성 해결
서로 다른 플랫폼에서 산출된 데이터를 전처리 없이 AI 모델에 입력하면 심각한 오류가 발생합니다. 각 실험 방법마다 판독 값(Readout)의 물리적 의미가 다르기 때문입니다.
플랫폼 간 데이터 불일치의 근본 원인
장비 특성에 따른 데이터 성질을 명확히 이해해야 합니다. 이질성을 제어하지 않으면 예측 모델의 정확도가 급격히 하락할 것으로 추정됩니다.
| 플랫폼 | 주요 판독 값 | AI 활용 특징 |
|---|---|---|
| SPR | KD, kon, koff | 정밀 동력학 측정, 절대 평가에 유리 |
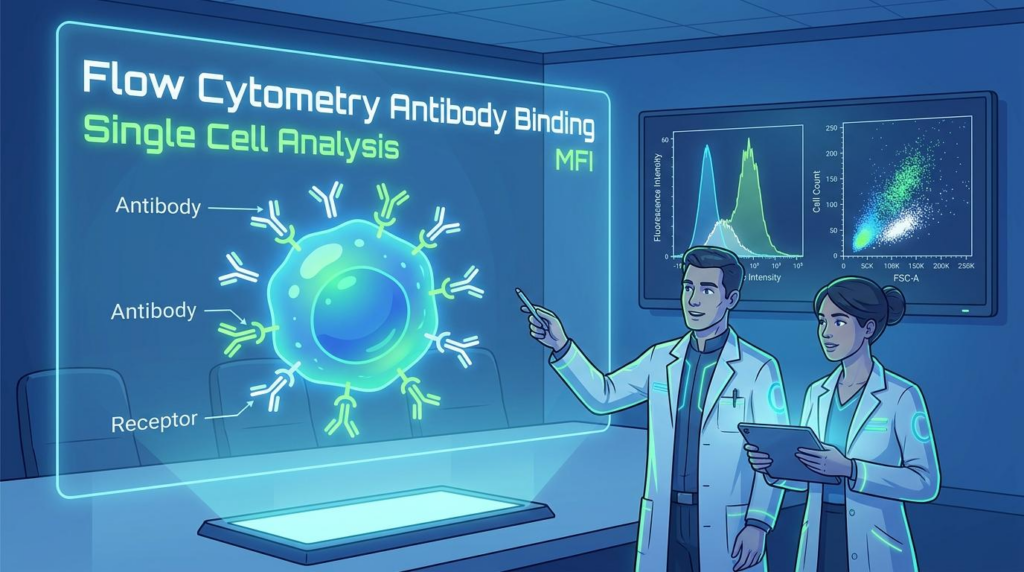
| FACS | MFI (형광 강도) | 세포 표면 환경 반영, 상대적 순위화 적합 |
| ELISA | OD, EC50 | 대량 스크리닝 최적화, 비용 효율성 우수 |
데이터 표준화 및 변환 전략
이질성을 극복하기 위해 로그 스케일 변환을 적용합니다. 이는 KD 값의 넓은 범위를 정규화하여 분산을 줄여줍니다. 또한 단위 통합을 위해 절대값이 아닌 상대적 순위(Ranking) 변환 기법을 사용합니다.
[Pro-tip] 연구 현장 실무 가이드: 기준 항체(Reference Antibody)를 반드시 설정하십시오. 기준 항체를 활용한 교차 보정(Calibration)을 수행하면 서로 다른 날짜와 플랫폼에서 측정한 데이터를 일관된 기준으로 통합할 수 있습니다.
4. 데이터 품질 관리(QC): 이상치 제거와 배치 효과
입력 데이터의 품질은 AI 모델의 성패를 좌우합니다. 쓰레기 값이 들어가면 쓰레기 결과가 나온다는 원칙은 바이오 데이터에도 동일하게 적용됩니다.
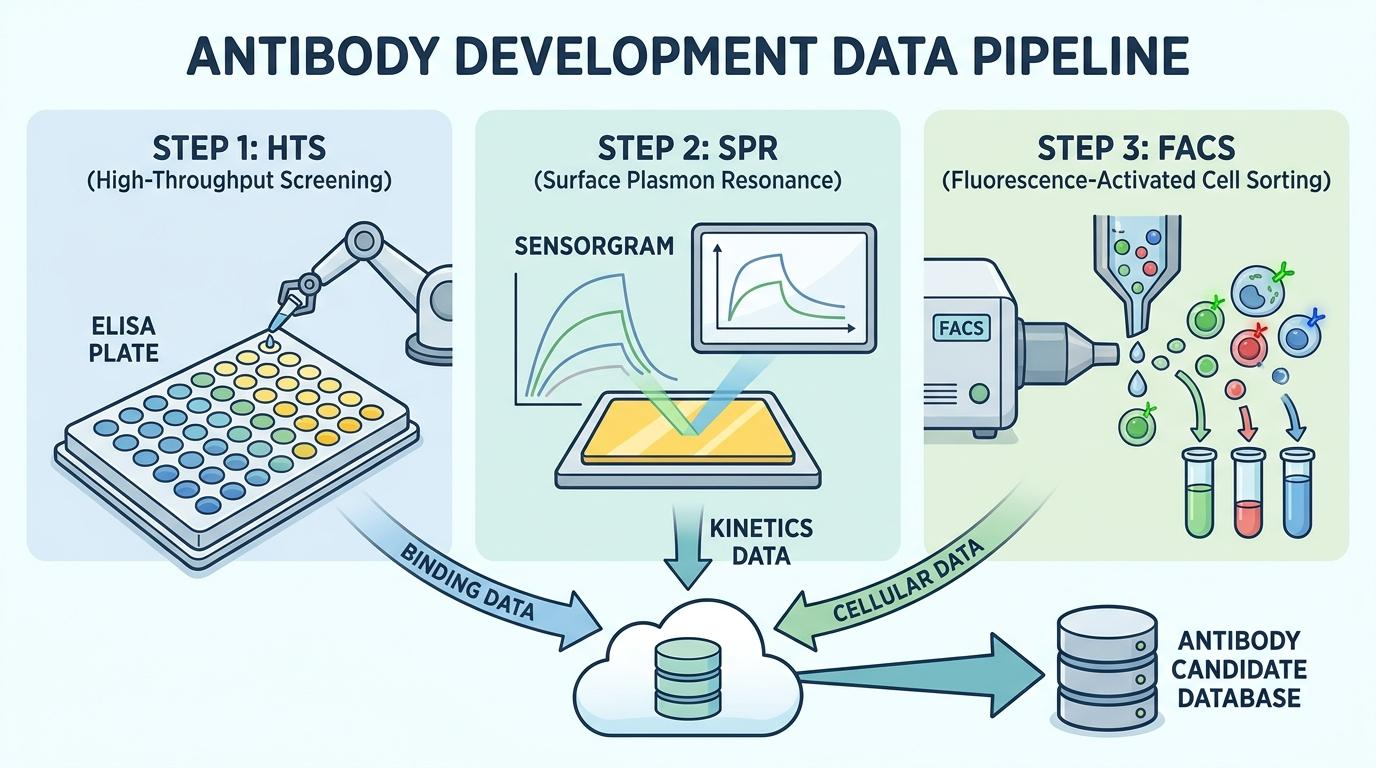
[그림 1] HTS, SPR, FACS 기반 3단계 데이터 확보 파이프라인 흐름도
이상치(Outlier) 통계적 제거 전략
Z-score(±3 표준편차)와 사분위수 범위(IQR)를 활용하여 기계적인 이상치를 걸러냅니다. 또한 플랫폼 고유의 인공물(Artifact)을 식별해야 합니다. SPR의 장비 표류(Drift) 현상이나 FACS의 자가형광 데이터는 훈련 세트에서 배제해야 합니다.
배치 효과(Batch Effect) 보정 기법
실험 날짜나 작업자에 따라 발생하는 배치 효과를 통제해야 합니다. ComBat 또는 Harmony와 같은 알고리즘을 사용하여 기술적 차이를 회귀 분석으로 보정합니다. 보정 후에는 PCA 분석을 통해 군집화가 정상적으로 이루어졌는지 확인합니다.
5. 라벨링 전략: 지도 및 자기 지도 학습 설계
준비된 데이터를 AI 모델이 이해할 수 있는 형태로 매핑(Mapping)하는 과정이 필요합니다. 학습 목적에 따라 라벨링 전략을 유연하게 적용해야 합니다.
지도 학습(Supervised Learning)의 적용
결합력 수치나 중화능과 같이 명확한 실험 결과 라벨을 부여합니다. 주로 내부 실험 데이터가 사용됩니다. 이 방식은 특정 항원에 대한 결합 여부를 예측하는 이진 분류 모델 훈련에 효과적입니다.
[추천 자료] 정확한 라벨링을 위해서는 데이터의 물리화학적 의미를 이해해야 합니다. 항체 개발 필수 지표, KD 값 계산 원리와 데이터 해석 방법에 대한 심층 자료를 검토하여 라벨링의 정확도를 높여보십시오.
상세 자료 확인하기자기 지도 학습(Self-supervised Learning) 융합
라벨이 없는 수천만 개의 면역 레퍼토리 서열을 활용합니다. 언어 모델이 문법을 배우듯, AI가 서열의 내부 구조를 스스로 학습합니다. 이후 지도 학습을 통해 미세 조정을 수행하는 융합 전략이 최근 우수한 성과를 보이고 있습니다.
6. 실무 관점: 항체 데이터 세트 구축 5단계 전략
이론적 지식을 바탕으로 실험실에서 바로 실행할 수 있는 데이터 통합 구축 전략을 5단계로 정리합니다.
성공적인 구축을 위한 워크플로우
- 1단계: SAbDab 및 OAS 공개 데이터로 모델의 사전 학습을 진행합니다.
- 2단계: 정제된 내부 실험 데이터를 주입하여 미세 조정을 실시합니다.
- 3단계: SPR에서 FACS로 이어지는 이기종 데이터 간의 교차 검증을 수행합니다.
- 4단계: AI 예측 결과를 실험으로 확인하고 모델을 재학습하는 순환 과정을 거칩니다.
- 5단계: CHIMERA-Bench 등 표준화된 테스트 세트로 객관적인 성능을 평가합니다.
[추천 자료] 동물 모델을 대체하는 혁신적인 평가법에 대한 글로벌 규제 동향을 파악하십시오. FDA NAMs 역사와 현재 규정: 동물실험 대체 가이드를 통해 세포 기반 검증 데이터의 규제적 가치를 확인하실 수 있습니다.
상세 자료 확인하기7. 결론: 고품질 데이터가 우수한 항체를 도출합니다
AI 항체 개발의 핵심 경쟁력은 알고리즘의 복잡성이 아니라, 주입되는 데이터의 무결성에 있습니다. 내부와 외부 데이터를 지능적으로 융합하고, 플랫폼 간의 편차를 수학적으로 보정해야 합니다. 이러한 체계적인 데이터 구축 시스템을 갖춘 조직만이 신약 개발 타임라인을 혁신적으로 단축할 수 있습니다.
파편화된 실험 데이터를 AI 친화적인 정밀 데이터셋으로 변환하고 싶으신가요? 결합 동력학 분석부터 데이터 통합 프로세스까지, 귀사의 항체 파이프라인 성공을 위한 맞춤형 데이터 솔루션을 제안해 드립니다. 전문가의 자문을 받아보십시오.
맞춤형 분석 솔루션 문의하기연관 토론 주제
- 다중 생물물리학적 데이터를 활용한 항체 Development 지표 개선 방안
- 자연어 처리(NLP) 기반 항체 언어 모델의 한계점과 극복 과제
- 고처리량(HTS) 데이터 생성 시 발생하는 배치 효과 보정 알고리즘 비교
핵심 용어 정리 (Glossary)
- 결합 동력학 (Binding Kinetics): 항체와 항원이 결합하고 해리되는 속도 및 친화력을 수학적으로 나타낸 지표입니다. 주로 SPR 장비를 통해 측정됩니다.
- 배치 효과 (Batch Effect): 생물학적 요인이 아닌, 실험 날짜, 장비, 연구자 등 기술적 요인에 의해 발생하는 데이터의 시스템적 편차를 의미합니다.
- 자기 지도 학습 (Self-supervised Learning): 정답(라벨)이 주어지지 않은 방대한 데이터 속에서 인공지능이 스스로 패턴과 구조를 찾아내어 학습하는 방법론입니다.
자주 묻는 질문 (FAQ)
Q. 공개 데이터베이스만으로 상용 항체 설계 모델을 구축할 수 있습니까?
A. 현실적으로 어렵습니다. 공개 데이터는 기본 구조 학습에 유용하지만, 특정 표적에 최적화된 결합력을 예측하려면 자체적으로 생성한 고순도 미세 조정(Fine-tuning) 데이터가 반드시 결합되어야 합니다.
Q. SPR과 FACS 데이터 중 AI 훈련에 더 적합한 기준은 무엇입니까?
A. 두 가지 모두 필요합니다. SPR은 절대적인 분자 간 상호작용 지표를 제공하고, FACS는 실제 세포 표면에서의 입체적 방해를 반영합니다. 두 데이터를 교차 보정하여 모델에 입력하는 것이 가장 이상적인 방법입니다.
Q. 데이터 이상치(Outlier)를 너무 많이 제거하면 모델 편향이 발생하지 않습니까?
A. 발생할 수 있습니다. 따라서 단순한 통계적 기준(Z-score 등)에만 의존하지 말고, 생물학적 메커니즘을 고려하여 비정상적인 데이터 파형만을 선별적으로 제거하는 것이 중요합니다.
문의 QR 코드 (메시지 연결)
주요 참고문헌
- Kovaltsuk, A., et al. (2018). Observed Antibody Space: A Resource for Data Mining Next-Generation Sequencing of Antibody Repertoires. The Journal of Immunology, 201(8), 2502-2509.
- Raybould, M. I. J., et al. (2019). Five computational developability guidelines for therapeutic antibody profiling. Proceedings of the National Academy of Sciences, 116(10), 4025-4030.
- Leek, J. T., et al. (2010). Tackling the widespread and critical impact of batch effects in high-throughput data. Nature Reviews Genetics, 11(10), 733-739.
* 본 게시물에 언급된 상표 및 분석 장비 명칭은 해당 소유권자의 자산이며, 정보 제공의 목적으로만 사용되었습니다.