AI 항체 개발 파이프라인에서 알고리즘보다 중요한 것은 데이터의 구조와 품질입니다. 방대한 바이오 빅데이터(Bio Big Data)를 활용하더라도 데이터 이질성을 통제하지 못하면 정확한 예측이 불가능에 가깝습니다. 본 포스팅에서는 결합 동역학(Binding Kinetics) 데이터의 희소성 문제를 분석하고 신뢰할 수 있는 데이터 전처리 전략을 제시합니다.
인사이트 키워드: AI 항체 개발, 데이터 이질성, 결합 동역학, 신약 개발
목차
1. AI 항체 개발과 바이오 빅데이터의 역설
단백질 구조를 예측하는 인공지능(AI) 시대가 열렸습니다. 하지만 신약 개발(Drug Discovery) 파이프라인에 AI를 도입한 실무자들은 종종 한계에 직면합니다. 입력 데이터가 불량하면 출력도 불량한 현상이 생물학 데이터에서도 그대로 재현됩니다.
1.1 겉보기 규모와 실제 품질의 차이
AI 모델의 성능은 바이오 빅데이터(Bio Big Data) 환경에 절대적으로 의존합니다. 차세대 염기서열 분석(NGS) 데이터는 수천만 건 이상 축적되어 있습니다. 하지만 표적 결합력이 명확히 검증된 고품질 기능 데이터는 극소수에 불과합니다. 문법 구조만 학습하고 진정한 생물학적 의미는 파악하지 못한 AI 모델은 실패할 확률이 높습니다.
2. 데이터 이질성이 신약 개발 AI에 미치는 영향
공개 데이터베이스를 무분별하게 혼합하면 심각한 부작용이 발생합니다. SAbDab이나 PDB 같은 공개 데이터는 출처와 실험 환경이 모두 다릅니다. 이를 데이터 이질성(Data Heterogeneity)이라고 명명합니다.
2.1 측정 환경 차이와 AI 오학습
연구실마다 사용하는 장비와 프로토콜이 다릅니다. 이로 인해 동일한 물질이라도 측정되는 절대값에 차이가 발생합니다. 이러한 배치 효과(Batch effect)를 보정하지 않고 AI에 학습시키면 모델은 잘못된 패턴을 정답으로 인식합니다.
[Pro-tip] 연구 현장 실무 가이드: AI 학습 전, 공개 데이터베이스의 결합력 수치를 정규화(Normalization)하는 과정이 필수적입니다. 참조 물질(Reference material)을 기준으로 각 데이터셋의 편차를 우선 보정하십시오.
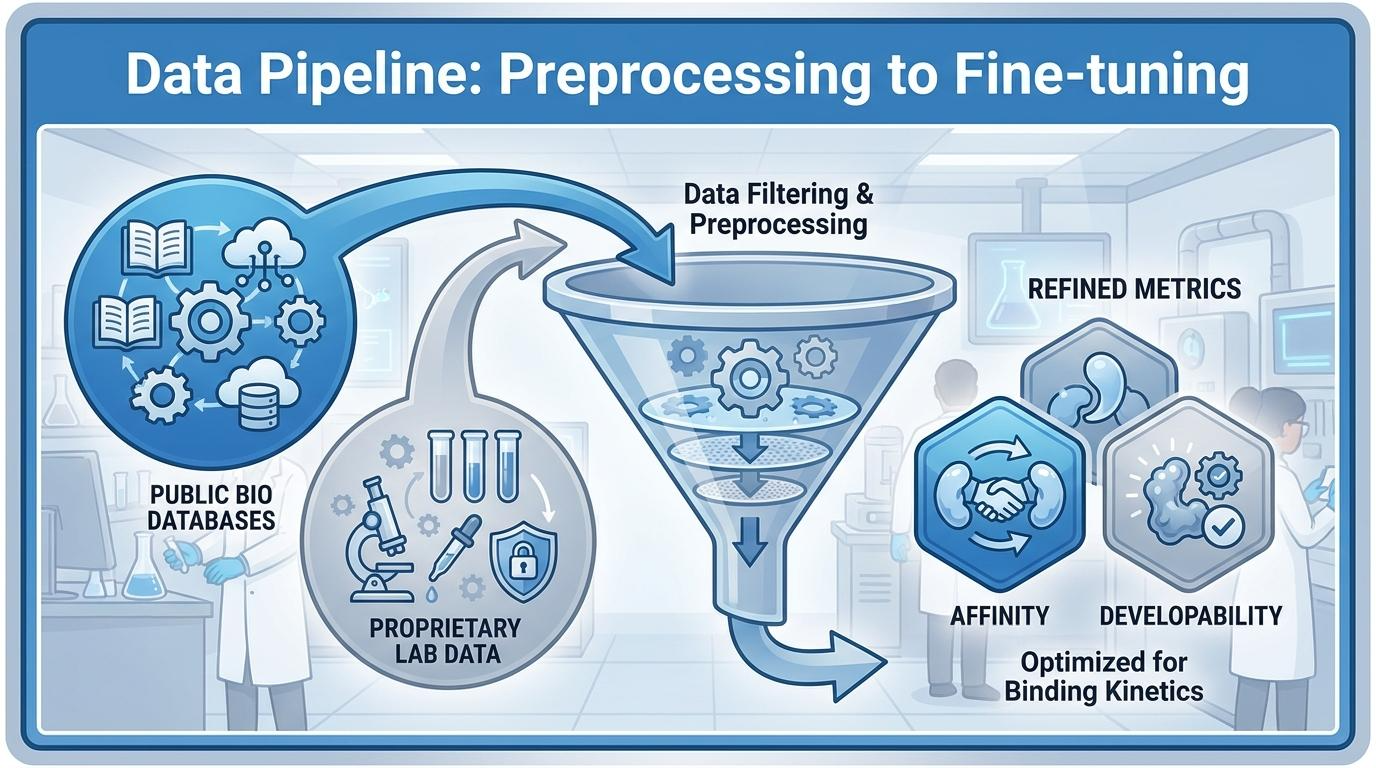
[그림 1] 이질적 데이터 정제 및 결합 동역학 파이프라인 모식도
3. 핵심 병목 현상과 결합 동역학 데이터의 희소성
단순히 항원과 항체의 결합 여부를 예측하는 모델로는 실제 치료제를 만들기 어렵습니다. 상업적 신약 개발을 위해서는 개발 가능성(Developability) 데이터를 반드시 확보해야 합니다.
3.1 친화도와 물성 평가의 복잡성
정밀한 약물 효능을 예측하려면 표면 플라즈몬 공명(Surface Plasmon Resonance, SPR)과 같은 분석법이 필요합니다. 단순한 평형 결합 상수(KD) 값 하나만으로는 생체 내 반응을 온전히 대변할 수 없기 때문입니다.
[추천 자료] 정확한 항체 효능을 평가하려면 KD 값의 산출 원리를 깊이 이해해야 합니다. 다음 링크에서 항체 개발 필수 지표, KD 값 계산 원리와 데이터 해석 방법을 자세히 확인해 보십시오.
상세 자료 확인하기3.2 결합 동역학 수치의 확보 난이도
약물의 타겟 체류 시간을 결정하는 결합 속도(kon)와 해리 속도(koff) 지표는 매우 중요합니다. 단백질 응집성(Aggregation) 같은 물리화학적 속성 데이터 역시 필수적입니다. 하지만 이러한 데이터는 획득에 막대한 비용과 시간이 소모됩니다. 따라서 AI 학습에 필요한 데이터 세트가 심각하게 부족한 상황입니다.
[추천 자료] 고가의 SPR 장비 없이도 초기 스크리닝 단계에서 유효한 결합 데이터를 얻는 전략이 필요합니다. Microplate Reader KD 측정 가이드를 통해 실무적인 대안을 탐색해 보십시오.
상세 자료 확인하기4. 현실적인 데이터 파이프라인 최적화 전략
막연한 AI 기술 도입을 경계하고 체계적인 데이터 파이프라인을 구축해야 합니다. 전처리 과정의 고도화가 알고리즘 개선보다 더 큰 성과를 창출할 가능성이 제기되었습니다.
4.1 전처리 파이프라인 및 투트랙 운영
먼저 이질적인 형식의 데이터를 통일하는 전처리 파이프라인(Preprocessing Pipeline)을 설계하십시오. 이후 데이터 속성에 맞추어 투트랙 전략을 실행하는 것이 바람직합니다. 대규모 공개 데이터로 기반 모델(Foundation Model)을 먼저 학습시킵니다.
| 데이터 종류 | 접근성 및 양 | 품질 및 일관성 | AI 파이프라인 적용 단계 |
|---|---|---|---|
| 공개 데이터 (Public Data) | 매우 높음 | 이질성 높음, 노이즈 존재 | 기반 모델의 사전 학습 (Pre-training) |
| 독점 데이터 (Proprietary Data) | 매우 낮음 | 일관성 높음, 고품질 검증 | 정밀 타겟 미세 조정 (Fine-tuning) |
사전 학습된 모델은 반드시 사내의 고품질 독점 데이터(Proprietary Data)로 미세 조정(Fine-tuning) 과정을 거쳐야 합니다. 이 과정에서 정밀 실험 장비로 도출된 결과를 사용해야 신뢰도가 확보됩니다.
[추천 자료] 세포막 수준의 결합 데이터를 구축하는 것은 모델 성능에 큰 영향을 미칩니다. 세포막 수용체와 재조합 단백질의 Binding Kinetics 차이 분석 문헌을 통해 생체 유사도를 높이는 방안을 검토하십시오.
상세 자료 확인하기4.2 능동 학습 기반의 효율적 루프 구축
실험실(Wet-lab) 역량을 효율적으로 배분하기 위해 능동 학습(Active Learning) 루프를 도입하십시오. AI가 예측 결론을 내리기 어려워하는 불확실성 높은 서열만 선별하여 실제 실험으로 검증합니다.
[추천 자료] Wet-lab 검증 단계에서 세포 기반 분석의 일관성을 높이는 기술이 요구됩니다. 유세포분석(Flow Cytometry) 원리와 FACS 완벽 가이드를 참고하여 고품질 세포 데이터를 확보하십시오.
상세 자료 확인하기동물 실험을 대체하려는 최신 규제 변화를 파악하는 것 또한 모델 설계 단계에서 중요합니다. 검증된 비동물 실험 기반의 데이터를 AI 학습 세트에 조기 반영하면 미래 규제 환경에 선제적으로 대응할 수 있습니다.
[추천 자료] 신약 개발 패러다임이 변화하고 있습니다. FDA NAMs 역사와 현재 규정을 확인하시고, 대체 시험법 데이터를 어떻게 AI 학습에 통합할 수 있을지 기획해 보십시오.
상세 자료 확인하기5. 결론 및 행동 유도
AI 항체 개발의 성패는 단지 복잡한 알고리즘을 도입하는 것에 있지 않습니다. 도메인 지식(Domain Knowledge)이 엄밀하게 반영된 데이터 엔지니어링 능력이 핵심 경쟁력으로 작용합니다. 데이터의 이질성을 극복하고 희소한 결합 동역학 지표를 체계적으로 자산화해야만 실질적인 신약 개발 성과를 도출할 수 있습니다.
현재 귀하의 연구실이나 소속 기업에서 AI 모델을 도입할 때 가장 큰 걸림돌이 되는 데이터 문제는 무엇입니까? 데이터 표준화와 정밀한 결합 동역학 평가를 통해 파이프라인의 완성도를 높이고 싶으시다면, 전문가와의 맞춤형 분석 논의를 시작해 보십시오.
맞춤형 분석 솔루션 문의하기연관 토론 주제
- 공개 단백질 데이터베이스(PDB)의 해상도 차이가 AI 예측 정확도에 미치는 영향
- 고품질 결합 동역학 데이터 확보를 위한 능동 학습(Active Learning) 적용 사례 비교
- 동물 실험 대체 시험법(NAMs) 데이터를 활용한 차세대 항체 물성 평가 모델 구축
핵심 용어 정리 (Glossary)
- 데이터 이질성 (Data Heterogeneity): 여러 출처에서 수집된 데이터가 형식, 단위, 측정 장비의 차이 등으로 인해 구조적, 질적으로 불일치하는 현상입니다.
- 결합 동역학 (Binding Kinetics): 분자 간의 결합과 해리가 일어나는 속도를 시간에 따라 분석하는 학문 분야입니다. 주로 표면 플라즈몬 공명 장비를 통해 측정됩니다.
- 능동 학습 (Active Learning): 인공지능 모델이 스스로 예측하기 가장 어려운 데이터 포인트를 선별하고, 사람(또는 실험실)에게 정답을 요청하여 효율적으로 성능을 향상시키는 기계 학습 방법론입니다.
자주 묻는 질문 (FAQ)
Q. AI로 항체 개발 시 딥러닝 알고리즘 성능보다 데이터 전처리가 더 중요합니까?
A. 그렇습니다. 생물학 데이터는 배치 효과로 인한 오차가 크기 때문에, 엄밀한 전처리 파이프라인 없이 최신 알고리즘만 적용하면 왜곡된 결과를 산출하게 됩니다.
Q. 공개 데이터(Public Data)만으로도 의미 있는 신약 후보 물질을 도출할 수 있습니까?
A. 초기 기초 모델을 학습시키는 데는 유용합니다. 하지만 최종 신약 후보 물질의 개발 가능성을 높이려면 반드시 사내의 정밀한 독점 데이터(Proprietary Data)로 미세 조정을 수행해야 합니다.
Q. 왜 단순한 KD 값 이외에 결합 속도(kon)와 해리 속도(koff) 지표가 필수적입니까?
A. 치료제가 실제 체내 환경에서 표적 단백질에 얼마나 오래 붙어 약효를 유지하는지 예측하기 위해서는 동적인 결합 및 해리 속도를 반영하는 정밀한 결합 동역학 정보가 필요하기 때문입니다.
문의 QR 코드 (메시지 연결)
주요 참고문헌
- Schneider, G. (2018). Automating drug discovery. Nature Reviews Drug Discovery, 17(2), 97-113.
- Marks, C., & Deane, C. M. (2020). Antibody H3 structure prediction. Computational and Structural Biotechnology Journal, 18, 2528-2537.
- Mason, J. M., et al. (2021). Optimization of therapeutic antibodies by predicting antigen specificity from amino acid sequence via deep learning. Nature Biomedical Engineering, 5(6), 600-612.
* 본 게시물에 언급된 상표 및 분석 장비, 데이터베이스 명칭은 해당 소유권자의 자산이며, 학술적 정보 제공의 목적으로만 사용되었습니다.