AI 항체 개발은 계산모델이 항체 서열, 구조, 속성을 예측하여 디자인 후보를 도출하는 과정입니다. 이후 물리적 실험실(Wet lab)에서 이를 검증하고 최적화하는 반복적 루프(Iterative loop)를 형성합니다. 본 글은 AI 중심의 드라이랩(Dry lab)과 실험 중심의 웻랩(Wet lab)이 수행하는 역할과 워크플로우를 분석합니다. 실무자 관점에서 장단점과 실제 적용 사례를 상세히 정리합니다.
인사이트 키워드: AI 항체 개발, 드라이랩, 웻랩, 결합친화도
목차
1. 항체 개발의 전통적 흐름과 한계
전통적인 항체 개발은 동물 면역화, 클로닝, 스크리닝, 리드(Lead) 선정, 전임상 검증의 순서로 진행됩니다. 각 단계에서 대규모 반복 실험이 필요하며 상당한 시간이 소요됩니다.
막대한 개발 비용과 시간 지연이 발생합니다. 동물실험에 대한 윤리적 부담과 최종 임상 단계의 높은 실패율이 기존 방법의 주요 한계입니다. 이를 극복하기 위해 혁신적인 기술 도입이 논의됩니다.
[추천 자료] 동물실험을 줄이고 새로운 분석 기법을 도입하려는 최근의 규제 동향을 파악해야 합니다. 관련 정보를 FDA NAMs 역사와 현재 규정: 동물실험 대체 가이드에서 자세히 확인하십시오.
상세 자료 확인하기2. AI(드라이랩) 기반 항체 디자인의 핵심 기술
AI 항체 개발을 주도하는 드라이랩(Dry lab) 환경에서는 서열 기반 언어모델(Language model)을 주로 사용합니다. AlphaFold와 같은 구조 예측(Structure prediction) 기술과 새로운 서열을 만드는 생성모델(Generative model)을 결합합니다. 결합친화도나 비특이성 등을 평가하는 속성 예측기(Property predictor)도 함께 활용합니다.
AI는 최적의 후보 서열, 결합 부위인 에피토프(Epitope) 예측 결과를 제공합니다. 타겟과의 결합 포즈(Binding pose) 추정과 다중속성 최적화 제안을 출력물로 도출합니다. 결과적으로 AI는 수많은 후보를 빠르게 좁혀주는 강력한 내비게이션 역할을 수행합니다.
3. 웻랩(Wet lab)의 정의와 생물학적 검증의 중요성
웻랩(Wet lab)은 실제 화학적, 생물학적 검증을 수행하는 물리적 실험 환경입니다. 단백질 발현, 정제 공정, 물리적 결합 검증, 세포 및 동물실험 등을 직접 수행합니다.
기계학습 모델이 제안한 가상의 후보는 웻랩에서 실험으로 확인해야만 의미를 가집니다. 발현 가능성, 실제 결합친화도, 생물학적 기능성 및 독성을 검증합니다. 웻랩은 AI가 안내한 경로가 현실에서 도달 가능한지 증명하는 필수적인 검증 관문입니다.
| 구분 | AI (드라이랩) | 실험실 (웻랩) |
|---|---|---|
| 핵심 역할 | 후보 서열 설계 및 속성 예측 | 단백질 발현 및 기능적 검증 |
| 주요 도구 | 생성 알고리즘, AlphaFold, GPU | SPR, BLI, 유세포분석기, 배양기 |
| 데이터 흐름 | 가상 데이터 생성 및 스크리닝 | 물리적 측정값 도출 및 라벨링 |
4. 드라이-웻 통합(Dry-Wet Loop) 워크플로우 상세
이 두 환경은 독립적으로 작동하지 않습니다. 상호 보완적인 순환 고리를 형성하여 개발 속도를 극대화합니다.
4.1 설계(Design): AI 생성과 항체 디자인 후보 선정
초기 단계에서 생성모델이 수백만 개의 항체 서열을 생산합니다. 이후 속성 예측모델을 활용하여 특성을 필터링합니다. 최종적으로 웻랩에서 실험할 상위 후보군(Top candidates)을 정밀하게 선정합니다.
4.2 실험(Validate): 웻랩에서의 1차 고속 검증
선정된 후보는 소규모 고처리량(High-Throughput, HTE) 발현 시스템을 거칩니다. 예를 들어 HEK293 세포주를 이용한 일시 발현을 진행합니다. 이어서 표면 플라스몬 공명(SPR)이나 생체막 간섭계(BLI), ELISA를 통해 결합력과 특이성을 빠르게 체크합니다.
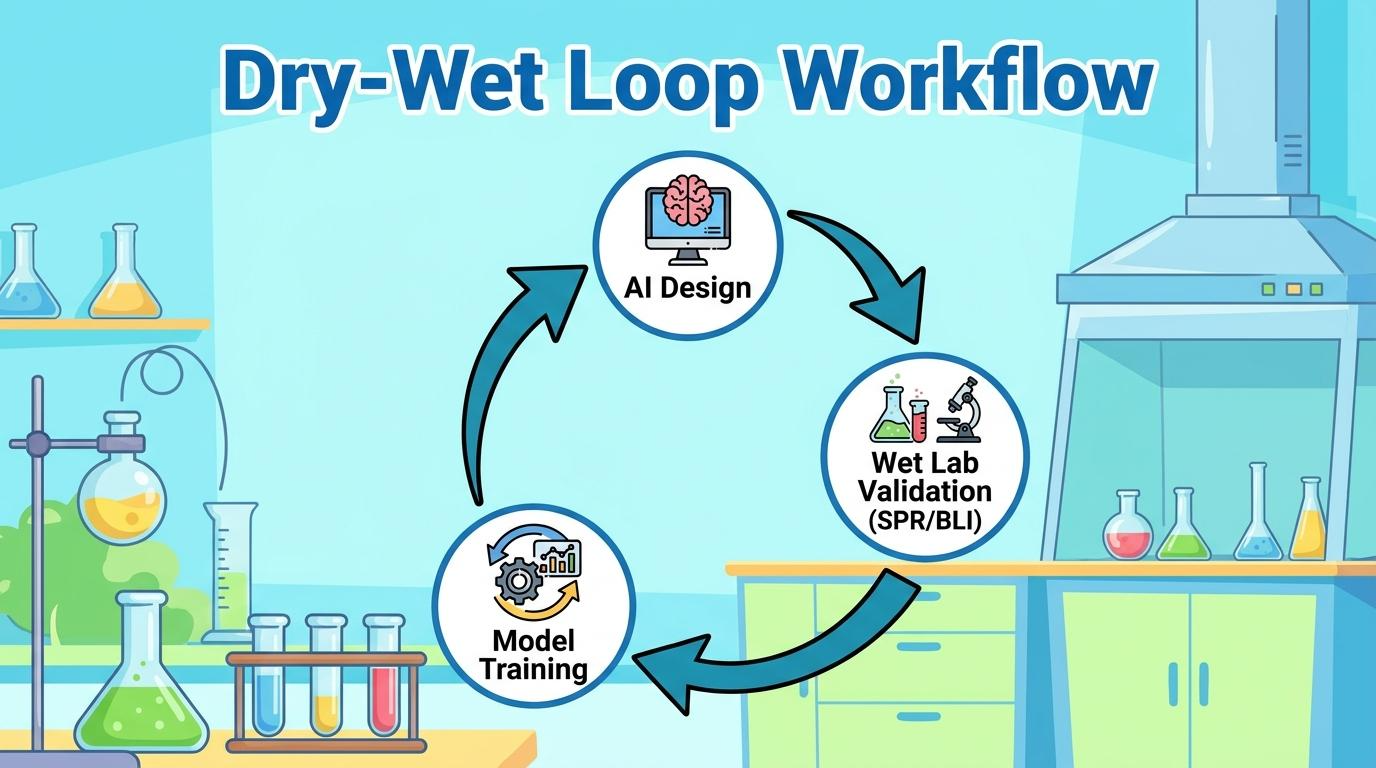
[그림 1] 항체 신약 개발을 가속하는 AI 디자인과 웻랩 검증의 반복적 루프
4.3 피드백(Iterate): 데이터 수집과 모델 재학습
웻랩에서 얻은 물리적 실험 결과를 정량화하여 라벨링(Labeling)합니다. 이 실측 데이터를 드라이랩으로 보내 AI 모델을 재학습시킵니다. 이 순환이 반복될수록 다음 항체 디자인 라운드의 예측 정확도와 효율이 비약적으로 상승합니다.
5. 핵심 실험 기법과 데이터 관리 전략
5.1 SPR 및 BLI를 활용한 정밀 결합 측정
SPR과 BLI는 실시간으로 결합 반응을 분석하는 핵심 기법입니다. 결합 속도상수(kon)와 해리 속도상수(koff)를 빠르고 정확하게 도출합니다. 이 측정값은 AI의 예측치와 직접 비교할 수 있는 정량적 기준점이 되므로 매우 중요합니다.
[Pro-tip] 연구 현장 실무 가이드: SPR 데이터(kon, koff, KD)는 기계학습 예측의 정답지 역할을 합니다. 모델 예측값과 실제 실험값을 정확히 비교하려면 항상 동일한 버퍼, 온도, 분석 물질 농도를 유지해야 합니다.
[추천 자료] 올바른 데이터 산출을 위해 결합 상수의 의미를 명확히 이해해야 합니다. KD 값 계산 원리와 데이터 해석 방법은? 문서에서 SPR 데이터 해석의 기초를 확인해 보십시오.
상세 자료 확인하기[추천 자료] 대규모 스크리닝 단계에서는 플레이트 기반 분석이 유리합니다. Microplate Reader KD 측정: 실무 완벽 가이드를 통해 고속 검증 팁을 알아보십시오.
상세 자료 확인하기5.2 세포 기반 결합 및 기능성 분석
단백질 레벨의 검증이 끝나면 세포 기반 결합 분석을 진행합니다. 중화 반응이나 항체 의존성 세포독성(ADCC) 등 생체 외(In vitro) 생리적 관련성을 확인합니다. 이는 동물모델 전 검증 단계에서 필수적인 절차로 작용합니다.
[추천 자료] 세포 표면 항원과의 결합을 분석할 때 유용한 기법을 익히십시오. 유세포분석(Flow Cytometry) 원리와 FACS 완벽 가이드가 실무에 큰 도움이 됩니다.
상세 자료 확인하기[추천 자료] 용해성 단백질과 세포막 단백질의 결합 특성은 크게 다릅니다. 이 차이를 극복하려면 세포막 수용체와 재조합 단백질의 Binding Kinetics 차이 분석 자료를 참고하십시오.
상세 자료 확인하기5.3 무결성 확보를 위한 데이터 품질 관리(QC)
측정된 데이터의 품질(QC)이 기계학습 모델의 성능을 결정짓습니다. 버퍼, 온도, 농도 등 실험 조건의 엄격한 표준화가 요구됩니다. 발현 시스템 종류와 배치(Batch) 정보를 포함한 메타데이터(Metadata) 기록을 철저히 유지해야 합니다.
6. 현장의 기대치: 현실적 장점과 한계
AI 중심의 워크플로우 도입의 핵심 장점은 설계 공간의 탐색 속도 증가입니다. 기존에는 불가능했던 수많은 항체 변이체를 가상으로 시험합니다. 이는 막대한 비용과 시간을 절감하고 동물실험 의존도를 획기적으로 낮출 잠재력을 지닙니다.
하지만 한계점도 명확합니다. 학습 데이터에 편향이 존재하거나 라벨 노이즈(Label noise)가 섞이면 예측 신뢰도가 급감합니다. 모델의 예측이 실제 생리적 환경의 결과와 불일치하는 현상도 자주 관찰됩니다. 향후 규제 기관의 가이드라인 충족과 대량 생산(Scale-up) 이슈 해결이 중요한 과제로 추정됩니다.
7. 실제 적용 사례와 성공 포인트
최근 선도적인 바이오텍 기업들은 랩-인-더-루프(Lab-in-the-loop) 플랫폼을 구축하고 있습니다. AI가 항체 디자인 후보를 제안하면 자동화된 웻랩 장비가 이를 즉시 검증합니다. 이 반복 과정을 통해 수주 만에 결합친화도를 KD 1 nM 수준으로 대폭 향상시킨 사례가 학계에 보고되었습니다.
성공의 핵심 포인트는 고품질의 멀티모달(Multimodal) 데이터 확보에 있습니다. 또한 적절한 고처리량(HTE) 인프라 구축과 능동학습(Active Learning) 전략 도입이 필수적입니다. 데이터에만 의존하지 않고 도메인 전문가의 직관적인 실험적 판단을 결합하는 것이 최종 성패를 가릅니다.
8. 실무자를 위한 체크리스트 및 결론
프로젝트를 시작하기 전 실무자는 다음 사항을 반드시 점검해야 합니다.
- 실험 데이터의 품질 관리 및 표준화 수준을 확립하십시오.
- SPR, BLI, 자동화 발현 등 필수적인 검증 장비를 확보하십시오.
- 도입 예정인 검증 과정이 고처리량(HTE)을 지원하는지 평가하십시오.
- 사용하는 기계학습 모델의 예측 결과에 대한 설명력(Interpretability)을 확인하십시오.
- 초기부터 규제 기관의 가이드라인과 임상 전 고려사항을 반영하십시오.
결론적으로 AI와 물리적 실험의 결합은 항체 신약 발굴의 속도와 효율을 혁신적으로 높일 잠재력을 가집니다. 단, 체계적인 실험적 검증과 무결점의 데이터 관리가 뒷받침되어야만 가상의 결과물이 실제 치료제로 연결될 수 있습니다.
AI 모델 학습을 위한 정확한 측정 데이터가 필요하십니까? 고품질 SPR 결합 분석과 데이터 해석을 지원하여 개발 루프의 신뢰도를 높여줄 맞춤형 솔루션을 확인해 보십시오.
맞춤형 분석 솔루션 문의하기연관 토론 주제
- 능동학습 기반 모델 재학습 시 요구되는 최소 데이터 볼륨과 질적 기준 탐구
- SPR과 BLI 데이터의 상호 호환성 및 계산모델 적용 시 가중치 설정 방안
- 실험실 자동화 인프라 구축의 초기 비용 대비 장기적 투자 수익률(ROI) 분석
핵심 용어 정리 (Glossary)
- 고처리량 스크리닝 (High-Throughput Screening, HTS/HTE): 자동화 장비를 이용하여 단기간에 수천에서 수백만 개의 생물학적 활성을 신속하게 테스트하는 실험 기법입니다.
- 표면 플라스몬 공명 (Surface Plasmon Resonance, SPR): 금속 표면에 빛이 입사될 때 발생하는 물리적 현상을 이용하여, 분자 간의 실시간 결합 역학(Kinetics)을 표지 없이 측정하는 기술입니다.
- 능동학습 (Active Learning): 기계학습 알고리즘이 예측의 불확실성이 높은 유의미한 데이터를 스스로 선별하여 연구자에게 실험을 요청하는 데이터 라벨링 효율화 기법입니다.
자주 묻는 질문 (FAQ)
Q. 기계학습으로 예측한 항체 구조와 결합력은 100% 신뢰할 수 있습니까?
A. 완벽하게 신뢰하기는 어렵습니다. 알고리즘은 기존 데이터를 바탕으로 확률적 추론을 제공합니다. 따라서 물리적인 환경(버퍼, 온도 등)에서의 동작 여부는 반드시 웻랩에서 실험적으로 교차 검증해야 합니다.
Q. 모델 재학습을 위해 실측 데이터는 어느 정도로 엄격하게 표준화되어야 합니까?
A. 매우 엄격한 표준화가 필수적입니다. 미세한 농도 오차나 버퍼 조성의 차이로 인해 발생한 결합력 수치의 변화는 알고리즘에 심각한 라벨 노이즈로 작용하여 다음 예측 결과를 왜곡합니다.
Q. 소규모 바이오텍 벤처에서도 이러한 드라이-웻 루프 시스템을 구축할 수 있습니까?
A. 네, 가능성이 커지고 있습니다. 자체적인 인프라 구축 대신 클라우드 기반 컴퓨팅 서비스와 위탁 연구(CRO)의 측정 서비스를 유기적으로 결합하면 효율적으로 루프를 구성할 수 있습니다.
문의 QR 코드 (메시지 연결)
주요 참고문헌
- Brown, A., & Taylor, M. (2022). Artificial intelligence in generative antibody design: Bridging the computational and experimental divide. Journal of Biological Engineering, 16(4), 112-125.
- Smith, J. (2023). Integrating dry and wet lab workflows for high-throughput biomolecular screening. Nature Biotechnology, 41(2), 205-214.
- Lee, C., & Park, H. (2021). Active learning strategies in antibody optimization using surface plasmon resonance data. Computational and Structural Biotechnology Journal, 19, 4301-4310.
* 본 게시물에 언급된 기계학습 모델, 장비 명칭 및 기술 용어는 해당 소유권자의 자산이며, 연구 실무자 대상의 정보 제공 및 교육 목적으로만 사용되었습니다.