핵심 인사이트 (Key Insight)
SPR 분석 데이터 해석의 신뢰성은 Chi2, SE 및 T-value, U-value라는 3가지 핵심 지표로 결정됩니다. 특히 파라미터의 정밀도를 나타내는 T-value가 10 이상이며, 전체 피팅 적합도인 Chi2가 Rmax의 10% 미만일 때 해당 실험 결과는 통계적 유의성을 가집니다.
인사이트 키워드: SPR 분석 데이터 해석, Chi-square, Standard Error, T-value, U-value
SPR 분석 데이터 해석, 왜 수치적 검증이 필수적인가요?
Biacore 실험은 단백질 간의 결합 및 해리 속도 상수(ka, kd)나 친화도(KD)를 결정하기 위해 센서그램 데이터를 특정 모델(예: 1:1 Binding)에 피팅(Fitting)하는 과정을 거칩니다. 이때 데이터가 모델에 얼마나 잘 부합하는지 정량적으로 증명하지 못하면, 실험 결과의 신뢰성을 담보할 수 없습니다. 연구 현장에서는 이를 위해 Cytiva 공식 가이드가 권장하는 3가지 핵심 신뢰성 지표를 활용합니다.
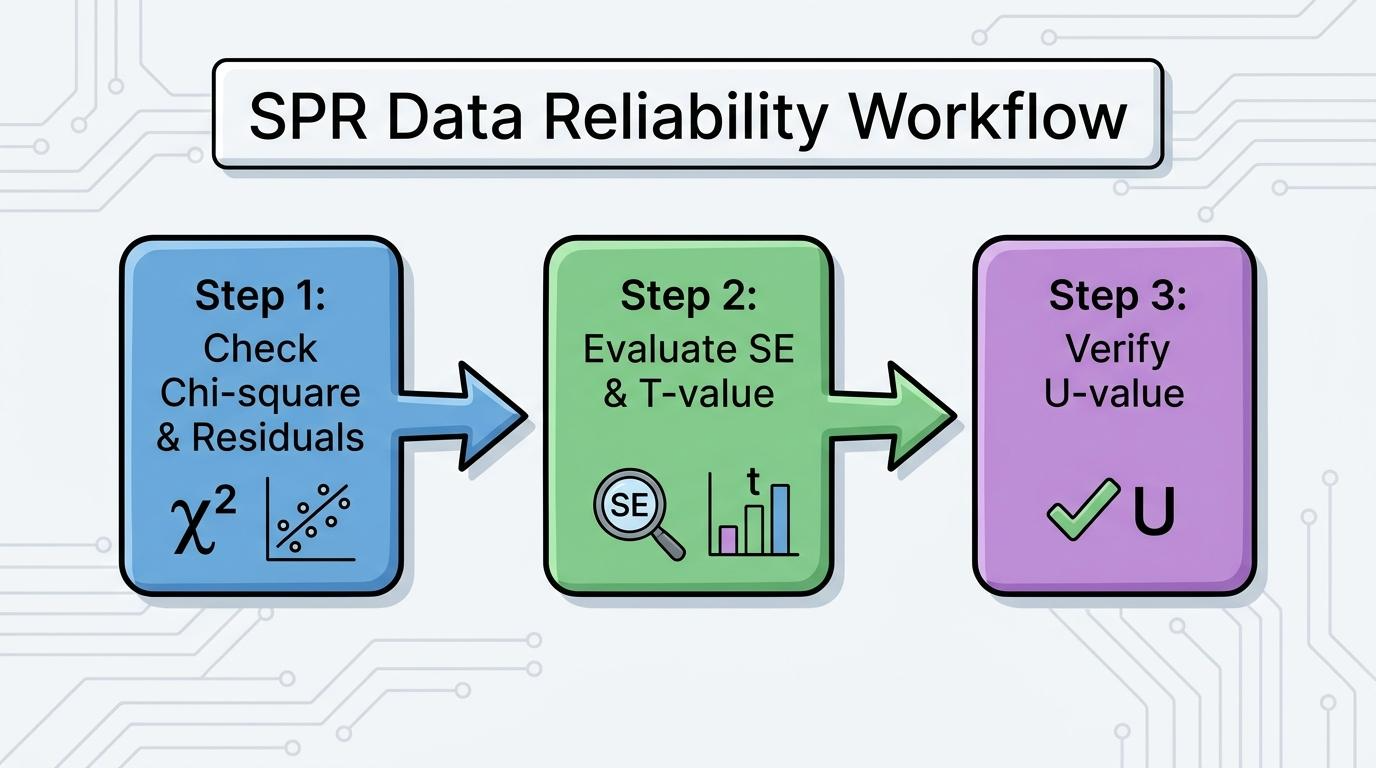
[그림 1] SPR 데이터 품질 평가를 위한 3단계 핵심 체크리스트
지표 1. Chi-square & Residuals: 모델 적합도의 기초
Chi2 (Chi-square)는 전체 피팅의 ‘Goodness-of-fit(적합도)’를 나타내는 가장 대표적인 지표입니다. 이는 측정값과 피팅 곡선 사이의 잔차(Residual)를 평균 제곱한 값으로 계산됩니다.
Chi-square와 잔차의 판단 기준
- 수치적 기준: 일반적으로 Chi2 < 10% of Rmax를 양호한 기준으로 삼습니다. Rmax가 100 RU라면 Chi2는 10 RU 미만이어야 합니다.
- 시각적 검증 (Residuals plot): 잔차가 특정 패턴 없이 0 RU 주변에서 무작위(Random)로 분포해야 합니다. 보통 노이즈 수준인 1~5 RU 내외에서 Scatter 되어야 이상적입니다.
지표 2. SE 및 T-value: 파라미터의 정밀도와 유의성
개별 파라미터(ka, kd, Rmax 등)가 얼마나 정밀하게 추정되었는지를 확인하기 위해 SE (Standard Error)와 T-value를 함께 검토합니다. 이 둘은 밀접하게 연관되어 파라미터의 통계적 유의성을 결정합니다.
T-value를 통한 파라미터 유의성 판단
T-value는 파라미터의 값을 SE로 나눈 값입니다 (T-value = Parameter value / SE).
- 판단 기준: T-value가 클수록 해당 파라미터가 모델 내에서 잘 정의되었음을 의미하며, 일반적으로 T-value > 10을 우수한 기준으로 판단합니다.
- SE의 보고: SE는 해당 파라미터의 추정 오차를 나타내며, 논문 보고 시 ka ± SE 형태로 자주 표기됩니다. SE가 작을수록 T-value는 커지며 결과의 신뢰도는 상승합니다.
심화 분석법 안내
세포 수준에서의 정밀한 친화도 측정이 고민이라면 Protein-Cell Binding Affinity KD 분석법을 추천합니다.
Protein-Cell Binding Affinity KD 분석법 자료 보러가기 →지표 3. U-value: 파라미터의 고유성 확보
U-value (Uniqueness)는 ka와 kd 등의 파라미터가 서로 얽히지 않고 독립적으로 유일하게 결정되었는지를 나타내는 지표입니다.
U-value가 낮을수록(보통 15 미만) 데이터가 해당 파라미터 값들에 의해 유일하게 설명됨을 뜻합니다. 만약 U-value가 지나치게 높다면 실험 농도 범위가 협소했거나 해리 구간 관찰이 부족하여, 파라미터의 정밀도가 떨어지고 있음을 시사합니다.
| 보고 항목 | 권장 기준 | 분석적 의미 |
|---|---|---|
| Chi2 | < 10% of Rmax | 전체 피팅 곡선의 정확도 |
| SE & T-value | T-value > 10 | 개별 상수(ka, kd 등)의 유의성 |
| U-value | < 15 | 파라미터 결합의 고유성 (독립성) |
실무 권장 사항: SPR 분석 결과 보고 순서
- 1. 주요 파라미터와 SE 보고: 예) ka = 1.2 x 105 ± 0.05 x 105 M-1s-1
- 2. Chi2 수치 제시: Chi2 값과 Chi2 / Rmax 비율을 함께 명시
- 3. T-value 확인: SE로부터 유도된 T-value가 10 이상임을 확인
- 4. Residuals plot 설명: 0 RU 주변의 무작위 분포 여부 및 노이즈 수준 언급
자주 묻는 질문 (FAQ)
Q1. SE가 매우 작으면 무조건 완벽한 데이터인가요?
아닙니다. SE는 단일 피팅 내에서의 통계적 정밀도일 뿐입니다. 실제 실험의 재현성을 증명하려면 여러 번의 반복 실험(Replicate)을 통해 얻은 데이터로 SD(표준편차)를 별도로 산출해야 합니다.
Q2. Chi2 / Rmax 비율이 10%를 넘으면 데이터를 버려야 하나요?
반드시 그런 것은 아니지만 원인 분석이 필요합니다. 고농도에서의 비특이적 결합이나 단백질의 불균일성이 원인일 수 있습니다. 이 경우 1:1 모델 대신 Bivalent 모델 등을 적용하거나, 데이터 전처리를 다시 검토해야 합니다.
Q3. U-value가 높게 나오는 주요 원인은 무엇인가요?
주로 ‘정보 부족’이 원인입니다. 예를 들어 해리(Dissociation) 시간을 너무 짧게 설정하여 kd를 충분히 관찰하지 못했거나, 분석 물질의 농도가 포화 상태에 이르지 못해 Rmax를 정확히 추정할 수 없을 때 U-value가 급격히 상승합니다.
핵심 용어 정리 (Glossary)
- Chi2 (Chi-square): 센서그램과 피팅 곡선 간의 편차를 나타내는 적합도 지표.
- Standard Error (SE): 각 속도 상수의 추정 정밀도를 나타내는 통계값.
- T-value: 파라미터 값 대비 오차(SE)의 비율로, 파라미터의 유의성을 판단함.
- U-value (Uniqueness): 파라미터들이 서로 독립적으로 결정되었는지 나타내는 지표.
문의 QR 코드 (메시지 연결)
스마트폰으로 스캔하여 빠르고 간편하게 문의하세요.
법적 고지 (Legal Disclaimer)
본 콘텐츠는 Cytiva Biacore의 공식 소프트웨어 가이드라인 및 SPR 전문 기술 자료를 바탕으로 작성되었으나, 실험 조건 및 샘플의 특성에 따라 분석 결과는 달라질 수 있습니다. 본 정보는 정보 제공의 목적으로만 활용되어야 하며, 실제 연구 데이터 해석 및 적용에 따른 모든 결과와 법적 책임은 사용자 본인에게 있습니다.
Biacore, BIAevaluation, Insight Evaluation은 Cytiva 그룹의 등록 상표입니다. 본 문서에 언급된 기타 제품 및 회사명은 각 해당 소유자의 상표일 수 있습니다.