핵심 인사이트 (Key Insight)
GraphPad Prism의 One-site Binding Model을 활용하십시오. Saturation Binding 데이터로부터 KD와 Bmax를 정확하게 추정할 수 있습니다. 비선형 회귀 방식을 통해 오차 왜곡을 완벽히 방지합니다. 본 가이드에서는 데이터 전처리부터 실패 분석까지 연구 현장의 실무 기준을 원스톱으로 제공합니다.
인사이트 키워드: One-site binding model KD 계산, saturation binding 피팅, nonlinear regression KD, Bmax KD Prism
One-site binding model KD 계산은 단백질 상호작용 분석의 기본입니다. 이는 리간드와 수용체 간의 평형 상태 결합 친화도(Binding Affinity)를 정량화하는 표준 방법론입니다.
Saturation Binding Assay 실험을 마친 뒤 원시 데이터를 얻습니다. 이를 정확한 수학적 모델에 대입해야 합니다. 통계적으로 타당한 KD 값을 구하는 과정은 데이터의 신뢰성을 결정합니다. 본 가이드에서는 코딩 없이 쉽고 정밀하게 비선형 회귀분석을 수행하는 프로토콜을 제시합니다.
왜 one-site binding model KD 계산에 GraphPad Prism을 사용하는가?
단일 결합 부위 모델을 설명하는 수식은 본질적으로 비선형 관계를 따릅니다. 과거에는 선형 변환 방식을 널리 썼습니다. 하지만 이 방식은 측정 오차를 심각하게 왜곡시킵니다. 따라서 현대 연구에서는 비선형 최소제곱법 알고리즘이 필요합니다. 전용 소프트웨어를 필수적으로 사용해야 합니다.
GraphPad Prism은 다양한 기술적 이점을 제공합니다. 이미 학계와 산업계의 표준 도구로 자리 잡았습니다. 구체적인 이점은 다음과 같습니다.
- 단일 결합 수식 기본 내장
- 파라미터 통계 정밀도를 위한 95% 신뢰 구간 자동 연산
- 피팅 강건성 검증을 위한 잔차 분포 그래프 생성
- 논문 규격을 충족하는 벡터 그래픽스 즉시 내보내기
연구실 실무 팁 (Pro-tip)
파이썬이나 R을 사용해서 동일한 연산을 수행할 수도 있습니다. 대량 스크리닝 자동화에는 프로그래밍 방식이 효율적입니다. 하지만 개별 플레이트 분석과 빠른 시각적 검증에는 여전히 Prism이 가장 유리합니다.
성공적인 saturation binding 피팅을 위한 원시 데이터 전처리
피팅 전에 데이터를 정밀하게 정리해야 합니다. 입력 데이터 형태가 올바르지 않으면 오류가 발생합니다. 특히 비특이적 결합(NSB)에 대한 정확한 정의와 제거가 필수입니다.
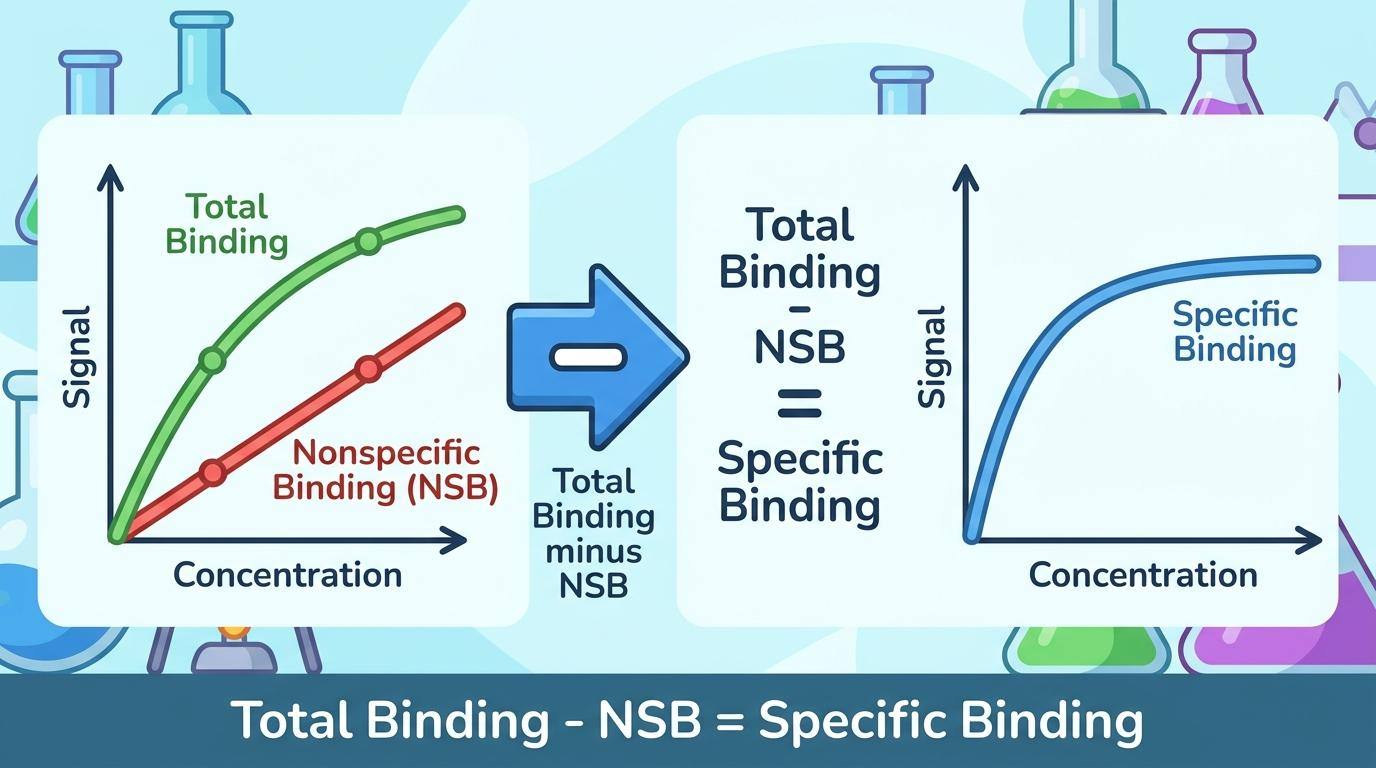
[그림 1] 원시 데이터에서 비특이적 결합을 감산하여 Specific Binding 데이터를 도출하는 워크플로우
데이터 입력을 준비할 때는 아래의 세 가지 검토 사항을 확실히 만족해야 합니다.
- 유효 결합 신호의 추출: Y값은 특정 표적에 결합한 순수 신호여야 합니다. 전체 결합(Total)에서 비특이적 결합(NSB)을 빼야 합니다. 이렇게 산출한 Specific Binding 값만 피팅에 사용하십시오. 그래야 왜곡 없는 참값을 얻습니다.
- 일관된 단위계 세팅: X축 농도와 Y축 신호 세기 단위는 완전히 고정해야 합니다. Prism은 입력한 단위를 그대로 결과로 냅니다. 단위를 혼용하면 잘못된 KD 값이 계산될 위험이 있습니다.
- 반복 데이터 처리: 중복 웰 데이터는 평균을 내지 않고 입력하는 것을 권장합니다. 개별 날것 데이터를 Prism에 그대로 입력하십시오. Prism이 자체적으로 오차를 계산하여 피팅 가중치를 알아서 조절합니다.
GraphPad Prism으로 nonlinear regression KD 분석을 수행하는 3단계
실제 Prism 환경에서 포화결합 데이터를 처리하는 과정입니다. 최적의 분석 결과를 도출하기 위한 구동 단계를 상세히 설명합니다.
Step 1. 데이터 테이블 생성 및 입력
Prism을 실행하고 New Table & Graph를 선택합니다. 상호작용의 종속 관계 분석을 위해 XY 유형의 템플릿을 선택합니다. X열에는 리간드 농도 값을 배정합니다. Y열에는 상응하는 신호값을 입력합니다. 반복 측정 수에 맞춰 Y 하위 컬럼의 개수도 설정해 줍니다.
Step 2. 비선형 회귀분석 알고리즘 적용
상단 메뉴에서 Analyze를 클릭합니다. Nonlinear regression (curve fit)을 선택하여 대화창을 엽니다. 좌측 수식 라이브러리 목록에서 Binding – Saturation을 탐색합니다. 실험 설계에 맞는 방정식을 아래 표를 참고해 지정해 주십시오.
| 선택할 모델명 | 적용 기준 및 수식 구조 | 특이 사항 |
|---|---|---|
| One site – Specific binding | Y = Bmax * X / (KD + X) | NSB 보정이 완료된 정제 데이터 분석 시 권장합니다. |
| One site – Total and NSB | Y = (Bmax * X / (KD + X)) + NS * X + Background | 총 결합량만 있을 때 선형 변수를 포함하여 피팅합니다. |
Step 3. 피팅 파라미터 제약조건 설정
OK 버튼을 누르기 전에 Constrain 탭을 확인합니다. 여기서 파라미터 물리 상수를 직접 제어할 수 있습니다. 예를 들어 결합 신호의 하한선은 0 미만이 될 수 없습니다. ‘Bottom을 0으로 고정’하면 미세한 오차로 인한 왜곡을 사전에 막아줍니다.
Bmax KD Prism 피팅 후 신뢰도 분석 및 잔차 평가
피팅 연산이 끝나면 Prism은 다양한 통계 변수를 보여줍니다. 결정계수(R2) 하나만 보고 적합도를 판단하면 위험합니다. 과학적 타당성을 검증하려면 다음 세 가지 항목을 함께 확인해야 합니다.
1. 결정계수 및 Sy.x 확인
R2값은 데이터의 정합도를 나타냅니다. 1에 가까울수록 적합도가 높습니다. 그러나 데이터 포인트가 적을 때는 결정계수가 왜곡될 수 있습니다. 실제 측정 오차의 분산 정보인 Sy.x 값을 함께 분석해야 합니다. 이 값이 허용 오차 한계 내에 있는지 꼭 확인하십시오.
2. 잔차 분석 패턴 규명
분석 옵션에서 잔차 그래프 그리기를 켭니다. 이상적인 잔차 플롯은 0을 기준으로 무작위 분포해야 합니다. 만약 잔차가 U자형을 그리거나 특정 구간에서 편향된다면 문제가 있습니다. 단일 결합 모델이 아니거나 평형에 도달하지 못했다는 강력한 신호입니다.
3. 95% 신뢰 구간의 과학적 해석
피팅 리포트에서 가장 집중해야 할 부분은 95% 신뢰구간(CI)의 범주입니다. KD 상숫값 자체보다 이 구간이 얼마나 좁게 잘 수렴했는지가 데이터의 실제 품질을 나타냅니다.
- 우수한 사례: KD = 15.2 nM (95% CI: 12.4 ~ 18.5 nM) – 파라미터가 좁게 제어되어 신뢰성이 매우 높습니다.
- 불안정한 사례: KD = 15.2 nM (95% CI: 1.5 ~ 152.0 nM) – 신뢰 범위가 너무 넓어 데이터 신뢰성에 결함이 있습니다.
자주 발생하는 피팅 오류 및 한계 돌파 전략
실험 과정에서 마주치는 가장 흔한 피팅 불능 원인을 규명하고 실질적인 대안을 제시합니다.
-
“Curve did not converge” 에러
원인: 알고리즘이 곡선의 평탄 영역을 찾지 못해 무한 루프에 빠졌습니다.
해결책: Initial Values 탭에서 초깃값을 직접 지정하십시오. 데이터상의 최대 Y값을 Bmax 초깃값으로 넣습니다. 최대 Y값의 절반에 달하는 X 좌표값을 KD 초깃값으로 대입하면 즉시 해결됩니다. -
추정 KD가 실험 최고 농도를 극단적으로 초과하는 경우
원인: 최고 리간드 농도가 너무 낮습니다. 이로 인해 포화 구간에 다다르지 못해 발생합니다.
해결책: 최고 농도를 과감하게 더 높여 재실험해야 합니다. 최소 예상되는 KD 값의 5~10배 농도까지 데이터 포인트를 넉넉히 확보하는 것이 이상적입니다. -
R2는 충분하나 오차가 거대한 현상
원인: 변곡점 부근의 데이터 조밀도가 희소하여 통계적 자유도를 얻지 못한 상태입니다.
해결책: 변곡점 부근인 20%~80% 결합 구간의 농도를 더 촘촘하게 쪼개어 데이터를 주입하십시오.
학술 논문 및 연구 보고서용 결과 기재 표준 양식
학술 논문이나 보고서에는 통계 모델과 소프트웨어 버전을 명시해야 합니다. 이는 글로벌 연구 가이드라인의 필수 조건입니다. 아래 표준 템플릿을 연구 데이터에 맞춰 활용하십시오.
영문 공식 표기 템플릿
“The KD value of the interaction was determined to be 18.4 nM (95% CI: 15.2 to 22.1 nM) via saturation binding assay. Non-linear regression curve fitting was executed using a one-site specific binding model with GraphPad Prism software (version 10.2.1, GraphPad Software, Boston, MA, USA).”
국문 기술 보고서 표기 템플릿
“타겟 단백질에 대한 리간드의 결합 평형상수(KD)는 Saturation Binding Assay를 기초로 도출되었습니다. 분석 결과 18.4 nM (95% 신뢰 구간: 15.2 ~ 22.1 nM)로 수렴하였습니다. 본 피팅은 비선형 회귀 모델인 One-site Specific Binding Model(GraphPad Prism 10.2.1)을 이용하였습니다.”
현대 생물학에서 Scatchard plot 분석을 지양해야 하는 이유
과거에는 Scatchard plot을 이용해 선형 방정식으로 KD를 추정하는 사례가 잦았습니다. 이는 컴퓨터 보급 이전 수작업을 위해 도입된 방식입니다. 이 선형 변환법은 오늘날 치명적인 통계 왜곡을 초래하는 원인으로 밝혀졌습니다.
Scatchard 방식은 독립 변수 데이터를 종속 변수 축에 중복으로 포함시킵니다. 수학적 독립성이 완전히 파괴됩니다. 이로 인해 낮은 농도 영역의 아주 미세한 실험 오차가 기하급수적으로 부풀려져 곡선이 크게 일그러집니다.
특히 실험에 비특이적 결합이 포함되면 왜곡이 한층 가중됩니다. 존재하지 않는 다상 결합 모델로 데이터를 잘못 인식할 가능성이 큽니다. 따라서 오늘날 학계에서는 Scatchard 방식의 수치 계산을 지양합니다. 반드시 비선형 회귀법을 표준으로 정립하십시오.
플레이트 분석 한계를 넘어 실제 환경을 모사하고 싶으십니까? 세포막의 유동성을 그대로 보존한 상태에서 실시간 결합(ka) 및 해리(kd) 상수를 관찰할 수 있는 전문 솔루션을 추천해 드립니다.
와이클루바이오만의 최첨단 분자 상호작용 분석 장비 기술 규격과 견적 문의는 아래 링크에서 즉시 확인 가능합니다.
와이클루바이오 분자 간 상호작용 실시간 SPR 분석 전문 서비스 자세히 보기
정제된 상태가 아닌 실제 생체 세포 표면(Living Cell Surface)에서 단백질과 약물 간의 바인딩 친화도 데이터를 극복하는 노하우가 필요하십니까? 기술 보고서 파일을 제공해 드립니다.
실험 시 오차를 극복하고 고수준의 프로파일링을 설계할 수 있는 비책이 궁금하시다면 아래 경로를 통해 상세 문헌을 취득하십시오.
Protein-Cell Binding Affinity KD 분석법 및 기술 백서 다운로드
불안정한 데이터 오차와 넓은 신뢰구간으로 논문 통과에 어려움을 겪고 계십니까?
불안정한 피팅 데이터 해결하기: 1:1 바인딩 어피니티 전문가 맞춤 진단 신청자주 묻는 질문 (FAQ)
Q1. R2값은 높게 설정되는데 KD 신뢰구간이 지나치게 넓게 나오는 이유가 무엇입니까?
A. 고농도 영역에서 포화(Plateau) 구간이 제대로 만들어지지 않았기 때문입니다. 가파르게 상승하는 구간 상태에서는 R2가 임시로 비대하게 상승합니다. 하지만 극대점인 Bmax를 수학적으로 지목할 수 없어 신뢰 범위가 수십 배로 벌어집니다. 실험 최고 농도를 최소 3배 이상 높여 대입해 주십시오.
Q2. ‘Specific binding’과 ‘Total and NSB’ 옵션 중 어떤 방식을 우선시해야 합니까?
A. 통계적으로는 개별 총 흡광 데이터(Total)와 대조군(NSB)을 통째로 기입하는 것이 정확합니다. 시스템이 한 번에 피팅하도록 ‘One site – Total and NSB’를 사용하는 편이 합리적입니다. 단, 연구실 자체의 감산 정제 규칙이 이미 확립되어 있다면 Specific binding 피팅을 사용해도 문제없습니다.
Q3. 결과창에서 KD 값이 마이너스 음수로 산출되는 것은 무엇 때문입니까?
A. 통계 알고리즘이 연산 불능 상태에 빠진 오류 현상입니다. 측정 데이터의 신호 크기가 백그라운드 노이즈보다 작을 때 주로 나타납니다. 또는 이상치(Outlier)가 요동쳐 곡선 피팅이 아래로 고꾸라진 탓입니다. 노이즈 포인트를 격리하거나 Constrain 설정을 통해 ‘KD > 0’ 조건을 적용하십시오.
핵심 용어 정리 (Glossary)
- KD (Dissociation Constant, 해리평형상수)
- 전체 표적 도메인의 50%가 결합 상태를 이루는 순간의 화학적 평형 물질 농도입니다. 이 수치가 낮을수록 결합 강도가 강력함을 증명합니다.
- Bmax (Maximum Binding Capacity, 최대 결합능)
- 이론상 무한대 농도 조건에서 표적의 모든 활성 영역이 결합했을 때 측정될 수 있는 최대 수렴 한계 수치입니다.
- Nonlinear Regression (비선형 회귀분석)
- 인위적인 직선 변환 없이 곡선 데이터를 고유의 방정식 모델에 정합시키는 수리적 분석 체계입니다. 현대 생체 열역학 실험의 표준 통계법입니다.
문의 QR 코드 (메시지 연결)
스마트폰으로 스캔하시면 바인딩 분석 긴급 진단을 위한 문자 메시지 전송 창으로 즉시 연동됩니다.
주요 참고 문헌 (References)
- Motulsky, H. J., & Brown, R. E. (2006). Detecting outliers when fitting curves with robust non-linear regression. BMC Bioinformatics, 7(1), 123.
- Hulme, E. C., & Trevethick, M. A. (2010). Ligand binding assays: Tools for drug discovery. British Journal of Pharmacology, 161(6), 1219-1237.
- Neubig, R. R., et al. (2003). International Union of Pharmacology Committee on Receptor Nomenclature and Drug Classification. XXXVIII. Update on terms and symbols in quantitative pharmacology. Pharmacological Reviews, 55(4), 597-606.